Online Proceedings
*Notice: PDF files are protected by password, please input "ipop2015.11th". Thank you.
Monday 20, April 2015
- Bijan Jabbari, iPOP General Co-Chair, ISOCORE, USA

Biography:
Currently CTO of Juniper Development and Innovation at Juniper Networks, Kireeti was formerly CTO at Contrail Systems, and before that, CTO and Chief
Architect of JunOS at Juniper Networks. Dr. Kompella has deep experience in Packet Transport, large-scale MPLS, VPNs, VPLS, and Layer 1 to Layer 3
networking, and has been very active in the IETF, as past chair of the CCAMP Working Group and as author of several Internet Drafts and RFCs across
several WGs (including CCAMP, IS-IS, L2VPN, MPLS, NVO3, OSPF, and TE).
Prior to Juniper, Kireeti worked on file systems at NetApp, SGI, and ACSC(acquired by Veritas).
Dr. Kompella received his BS EE and MS CS at IIT, Kanpur, and his PhD in Computer Science at USC, specializing in Number Theory and cryptography.

In the Internet, network providers provide both the network infrastructure and network services. Network providers
need to design the network infrastructure based on the peak demand to maintain stable service quality, so a large part
of network resources remain unused in off-peak hours such as late at night. Consequently, only leading companies
that can afford to invest a huge amount of money over a long period can construct the network infrastructure and
provide network services. However, with network virtualization, users of network resources, i.e., service providers
(SPs), can be separated from the owner of the network resources, i.e., infrastructure providers (InPs). In this case,
the network-service providers are not required to own the network infrastructure, and they can focus on providing
network services without constructing and managing the network infrastructure. This is expected to encourage small
and medium-sized enterprises to start various types of network services. However, to promote the separation between
owners and users of network resources, it is important to suitably define the management model of network resources
that is necessary in order to trade resources between InPs and SPs. Moreover, we need to suitably determine which
InP or SP carries out each of the operations required to provide the network services.
Therefore, in this presentation, to promote the separation between ownership and use of network resources, we
identify the requirements for a management model of network resources considering the aspects of both InPs and SPs,
and we propose a management model called allocation block, that satisfies these requirements as shown in Fig. 1.
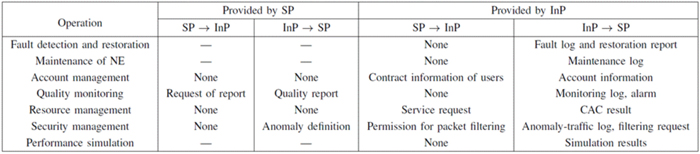
Moreover, we identify the requirements for the interface between SPs and InPs (shown by interface 5 in Fig. 2) for
various operations which will be commonly required when providing network services, and we discuss the possibility
that both of the players, the InP and SP, will provides each operation as well as the required information exchanged
at the interface between InP and SP as summarized in Tabs 1 and 2. Then, we show two extreme cases as examples
of the operation embodiment.
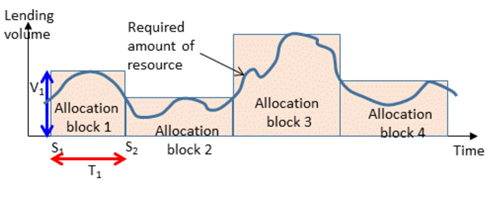
Fig.1 Example of set of allocation blocks
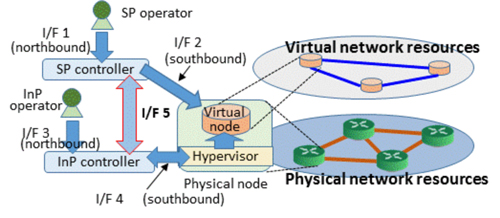
Fig.2 System architecture of virtualized network environment assumed in this paper
Tab.1 Required interface for operations related to network construction

Tab.2 Required interface for operations related to network management
![]()
Biography:
Noriaki Kamiyama received his M.E. and Ph.D. degrees in communications engineering from Osaka University in 1994 and 1996, respectively. From 1996 to 1997, he was with the University of Southern California as a visiting researcher. He joined NTT Multimedia Network Laboratories in 1997. From 2013, he is also with the Osaka University as an invited associate professor. He has been engaged in research concerning network economics, content distribution systems, optical networks, IP traffic measurement, and network design. He received the best paper award at the IFIP/IEEE IM 2013. He is a member of IEEE and IEICE.

Recent SDN efforts have typically focused on greenfield deployments using OpenFlow. Practically, the well-known concepts and subsequent benefits of SDN need to be realized for existing network technologies such as MPLS-TE and GMPLS, which are already widely deployed. Therefore, it is important to augment existing network technology with the capabilities of SDN including, resource slicing, end to end service provisioning (across server and client layers) and automation of service setup, resizing and tear-down.
Abstraction Control of Transport Networks (ACTN) is gathering significant industry support and provides a method for allowing key SDN benefits for deployed connection-orientated technologies. The ACTN reference model is described below:
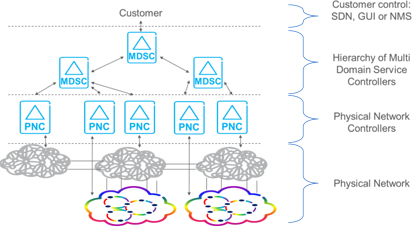
This reference model is comprised of two types of network controllers, namely the Physical Network Controller (PNC) and the Multi Domain Service Controller (MDSC). This facilitates the deployment of customer driven applications using the Customer Network Controller. These are discussed in more detail:
- The PNC is a domain control/management entity (e.g., GMPLS Control Plane plus Path Computation Element, Open Flow controller, Network Management System).
- The MDSC is the coordinator and orchestrator responsible for supporting customers' virtual networks creation, modification and deletion requests.
The ACTN architecture, unlike a distributed MPLS-TE or GMPLS control plane, does not deal with nodes and links only, but also with services. Two types of services are considered:
- Service-aware Connectivity Services: This category includes all the network service operations used to provide connectivity between customer end-points while meeting policies and service related constraints.
- Network Function Virtualization Services: These kinds of services are usually setup between customers' premises and service provider premises and are provided mostly by cloud providers or content delivery providers. They include resource slicing and Service Function Chaining (SFC).
This presentation outlines the current state of ACTN, including: recent developments towards standardization within the IETF, vendor implementations, research projects investigating ACTN. Finally, the presentation will outline and next steps and challenges for commercialization and research.
![]()
Biography:
Young Lee is currently Principal Technologist at Huawei Technologies USA Research Center, Plano, Texas since 2006. He is leading optical transport control plane technology research and development. His research interest includes SDN, cloud computing architecture, cross stratum optimization, network virtualization, distributed path computation architecture, multi-layer traffic engineering methodology, and network optimization modeling and new concept development in optical control plane signaling and routing. Prior to joining to Huawei Technologies, he was a co-founder and a Principal Architect at Ceterus Networks (2001-2005) where he developed topology discovery protocol and control plane architecture for optical transport core product. Prior to joining to Ceterus Networks, he was Principal Technical Staff Member at AT&T/Bell Labs in Middletown/Holmdel, New Jersey (1987-2000).
He is active in standardization of transport SDN, GMPLS, PCE in IETF and ONF and has driven Transport SDN both in industry, standardization and product development. He served a co-chair for IETF's ACTN BOF and a co-chair for ONF's NTDG.
He received B.A. degree in applied mathematics from the University of California at Berkeley in 1986, M.S. degree in operations research from Stanford University, Stanford, CA, in 1987, and Ph.D. degree in decision sciences and engineering systems from Rensselaer Polytechnic Institute, Troy, NY, in 1996.

As applications, such as video content distribution, big data and network function virtualization, are moving to the cloud, geographically distributed data centers are
being deployed and interconnected using optical networks, forming wide-area Information and Communications Technology (ICT) infrastructures. Virtualization is a
key technology in these infrastructures, which enable multiple tenants efficiently share both computing and network resources. However, although Virtual Machines
(VMs) are now the standard abstraction for sharing computing resources, the right abstraction for networks remains an open issue.
Software-defined Networking (SDN) [1] is a remarkable step towards network virtualization, which allows a network entity to be "software-defined" rather than manually
configured. For example, OpenFlow [2]'s FlowVisor [3] (and its successor OpenVirteX [4]) allows flexible "definition" of virtual networks. However, SDN in general, and
OpenFlow in particular, does not provide sufficient abstraction for network resources. What SDN defines are only the "properties" of each network entity, not the "behavior"
of the network entity. Due to the centralized-control nature of SDN, the behavior of a network entity (such as its packet-forwarding rules) must be controlled externally by
a SDN controller, not by the network entity itself. Such an approach fundamentally limits the flexibility and functionality of individual virtual network entity, as well as raises
scalability concerns for the centralized controller. The problem is further aggravated when introducing circuit-oriented controls (e.g., provisioning/scheduling, protection/restoration)
and optical layer considerations (e.g., reachability, quality-of-transmission monitoring), etc. into the virtual network entities (e.g., Virtual Optical Network provisioning [5]).
Accordingly, a more efficient and scalable solution is needed to support numerous concurrent virtual network entities with a wide variety of abstractions, while allowing each virtual
network to execute highly-flexible and speedy control logic on its own network slice.
We introduce a new virtual networking paradigm called Object-Oriented Network Virtualization (OONV). As shown in Fig. 1 [6], a virtual network entity is created and operated as a
"Virtual Network Object (VNO)." A VNO is a complete representation of a virtual network service throughout its lifecycle. In addition to its unique identity and properties, a VNO also
contains its behavior, which is a set of methods for executing its own functions. Such an object-oriented representation endows a VNO with two important characteristics: persistence
and autonomous control. Persistence provides native support for circuit-oriented functions such as state, scheduling, protection and restoration, etc. Autonomous control includes
self-monitoring, self-healing, self-adaptation, self-optimization, etc. In OONV, instead of software-defining a virtual network entity, a virtual network object is programmatically
instantiated from a VNO template (similar to new'ing an Object from a Class in an object-oriented programming language). For that reason, OONV makes it possible for Software-defined
Networking (SDN) to evolve into Software-programmed Networking (SPN). More specifically, SDN defines a virtual network entity as a collection of logical and physical properties and
operates it externally. In contrast, SPN programs a virtual network entity as a self-contained object that operates autonomously. We will present a proof-of-concept SPN OS prototype
demonstrating object-oriented virtual network services.
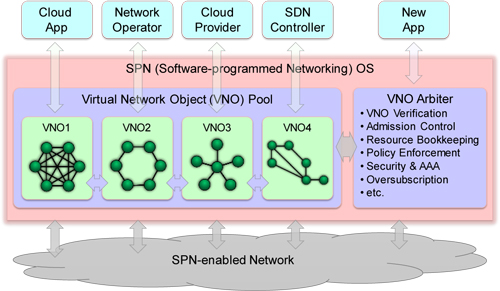
Fig1. The architectural view of Object-Oriented Network Virtualization for SPN
References:
- "Software-Defined Networking: The New Norm for Networks," white paper, Open Networking Foundation, April 13, 2012.
- N. McKeown, et al., "OpenFlow: enabling innovation in campus networks," SIGCOMM Computer Communication Review, April 2008.
- R. Sherwood, et al., "FlowVisor: A Network Virtualization Layer," http://archive.openflow.org/downloads/technicalreports/openflow-tr-2009-1-flowvisor.pdf
- "ON.LAB OpenVirteX (OVX)," http://www.sdncentral.com/projects/on-lab-openvirtex-ovx/
- X. Wang, Q. Zhang, I. Kim, P. Palacharla, and M. Sekiya, "Virtual Network Provisioning over Distance-Adaptive Flexible-Grid Optical Networks (Invited Paper)," Journal of Optical Communications and Networking (JOCN), Vol. 7, Iss. 2, pp. A318-A325 (2015).
- X. Wang, Q. Zhang, I. Kim, P. Palacharla, and M. Sekiya, "Object-oriented Network Virtualization – An Evolution from SDN to SPN (Invited Paper)," Photonic Networks and Devices (Networks) 2014 Paper NT1C.2, as part of the Advanced Photonics for Communications Congress, San Diego, California, July 2014.
![]()
Biography:
Xi Wang is a researcher in network system innovation group at Fujitsu Laboratories of America. His current research interests include software-defined networking, flexible ROADM architectures, packet optical networks, optical/wireless integration, and future photonic switching networks. He received B.S. degree from Doshisha University, and M.E. and Ph.D. degrees from the University of Tokyo in Information and Communication Engineering. Prior to joining Fujitsu, he was a postdoctoral researcher with the Electronic Visualization Laboratory, Computer Science Department at University of Illinois at Chicago. Dr. Wang is a member of IEEE Communications Society and has served as technical program committee member for OFC/NFOEC and other conferences.

This session includes a discussion of multiple SDN solutions for solving real problems in network use case scenarios. The common theme of the various use cases includes leveraging the Brocade Flow Optimizer Application, the Brocade Vyatta Controller and the OpenFlow v1.3 protocol to provide innovative solutions around traffic management of large volumetric traffic flows. Three use cases will be discussed:
- High volume L3/L4 DDoS detection and mitigation solution
- Intelligent Flow Management for large elephant flow solution (AKA: Science-DMZ)
- Network analytics traffic mirroring solution
Each of the three solutions leverages similar components and protocols; however, the components and functions are applied in different ways to solve distinctly different problems.
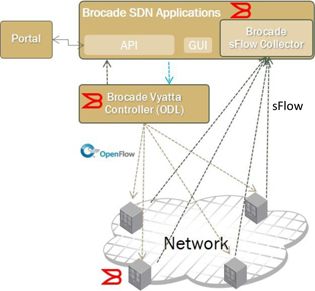
Fig.1 SDN Solution Components and Protocols
1. High Volume L3/L4 DDoS Detection and Mitigation
Distributed Denial of Service attacks are again becoming a more common threat to network infrastructure and resources. These high volume attacks not only disrupt service by disabling host machines and applications, but the attacks are simultaneously saturating network links and resources.
Brocade's SDN solution provides a near-real time and closed loop detection and mitigation solution; using open standard protocols such as sFlow and OpenFlow.
The attack profiles are L3/L4 high volume attacks; as these are the more common DDoS attack vectors that are proliferating in today's Internet and causing massive disruption to network services.
The primary component of this solution is the Brocade Flow Optimizer App.
This app receives sFlow datagram samples from the network switches and examines these flows to determine whether they match a configured DDoS profile.
Upon a positive DDoS detection, the SDN app automatically programs the network switches to discard the DDoS flows at the ingress of the network.
This programmatic response uses OpenFlow v1.3 rules. There is no need for operator intervention in this response.
This elegant solution provides an immediate L3/L4 DDoS mitigation service in the network routers themselves; as opposed to some of the existing solutions for this problem space, where additional external hardware devices are required. Many other advantages will be discussed in this session.
2. Intelligent Flow Management for Large Elephant Flow Detection and Redirection for Firewall Bypass (AKA: Science-DMZ [1])
Everyone is familiar with the need for Service Insertion and Service Chaining.
Equally important is the frequent need to bypass services, such as a firewall, for legitimate traffic flows that do not require the firewall services.
Many of the deployed firewalls struggle to keep pace with the large and long lived flows (AKA: Elephant flows) in today's networks.
More commonly, these elephant flows occur in large research and science networks; however, any large long lived flow could benefit from this type of bypass solution.
For example, Inter-Data Center bulk data transfers or backups commonly do not need the services of the enterprise firewall.
These elephant flows are detected in near real-time by the SDN application and OpenFlow rules are programmed into the network switches to redirect these elephant flows around the firewall.
This provides a dynamic and near real-time service bypass capability.
3. Network Analytics Traffic Mirroring
Network operators of all types require visibility into network traffic flows for various reasons, such as performance monitoring, troubleshooting and security analysis.
Today's visibility solutions are not very flexible in terms of where and when network flows can be mirrored for analysis. Often, hardware probes need to be deployed at various locations in the network to gain the needed network visibility. In addition, legacy mechanisms such as Policy-Based Routing (PBR) and port spanning are configured in each of the network switches to mirror select traffic to the network probes. There are many limitations to these current methods of gaining the traffic visibility needed for network analytics.
This solution leverages the Brocade Vyatta SDN platform and associated SDN application to push OpenFlow rules into the network switches to mirror selected traffic flows to specific switch ports where analytics devices are connected.
The normal IP forwarding of those flows is not affected; this function unobtrusively mirrors the flows. This can be extended in the future to provide the ability to encapsulate the mirrored network traffic for a remote mirroring solution.
The OpenFlow based mirroring functionality is provided at line rate with no performance impact, and is it not subject to the current limitations of today's mechanisms (PBR and port spanning).
Summary:
Each of these use cases and their associated solutions will be discussed. Included with the discussion will be embedded demonstration videos of the solutions in action. These novel solutions will demonstrate how OpenFlow and SDN are being used to solve real life network problems.
Related references and publications:
- Science-DMZ Architecture, http://fasterdata.es.net/science-dmz/
- "OpenDaylight Open Source Software," http://www.opendaylight.org/
- "Behavioral Security Threat Detection Strategies for Data Center Switches and Routers," IEEE International Workshop on Data Center Performance (DCPerf'14), http://ieeexplore.ieee.org/xpl/articleDetails.jsp?arnumber=6888844
![]()
Biography:
Pete Moyer is Principal Solutions Architect and Member of Extended CTO Office, Brocade.
Pete has more than 15 years' experience in IP & MPLS networking, with 3+ years in OpenFlow and SDN. He possesses in depth IP/MPLS service provider experience in network architecture, design and implementation. He has both the Cisco CCIE #3286 and the Juniper JNCIE #2 certifications; and in fact, was the first certified JNCIE. He delivers network architecture consulting solutions to global service providers and large enterprises. He assisted in the creation of some of the innovative SDN solutions that are now coming to market. Pete is also a co-author and technical editor of multiple IP networking books.
Prior to joining Brocade, Pete was at Juniper Networks for roughly 10 years. He holds a Bachelor of Science degree in Computer and Information Systems from the University of Maryland.

For most of the time, optical network has been playing a role of transportation due to the lack of elasticity. Network
virtualization1 and SDN2 technique have provided an approach for creating a controllable network plane from the
static physical layer. However, with various service provisioning requirements in the dynamically created virtual
optical networks1 (VON), the number and complexity of controllers increase. It is neither cost-effective nor scalable
to add or modify a controller whenever a new service is required in the VON. Therefore, we introduce an elastic
architecture to provide network services3 for the dynamic VONs in an adaptive plug-in mode.
As shown in Fig. 1, WDM network is virtualized using Flowvisor4, which creates isolated VONs by carving the
physical network into multiple slices to be managed by separate controllers. An additional network service
provisioning layer is introduced in the control plane, where various network service modules (NSM) are deployed in
a plug-in manner, as they are sharable and reusable among different VONs and each VON is able to associate with
different or common set of NSMs depending on the service requirements. These NSMs can provide various service
functions such as protection, multicast and modulation format configuration in the optical network, or just enforce
certain policy on the controller for constraint routing, etc. Such structure reduces the controller complexity and the
deployment cost, while improves the network scalability. Traffic flows are classified and labeled before
transmission (defined by orchestrator/operator), and recognized in the controller afterwards, where matching NSMs
are found and required service functions are applied to this traffic flow.
As an example shown in Fig. 1, we demonstrate the protection service accommodation in the optical network.
Optical network is virtualized into two VONs and a sharable protection service is enabled in NSM_1. When labeled
traffic flow f1 enters the network, the controller finds a match of NSM_1 using the label, and NSM_1 calculates a
protection path for f1. Thus the controller configures two paths in VON1 (path 1-3 and path 1-4-3). The Flowtable
modification messages2 in Fig. 1 shows the setup of optical cross connects (OXC) along two paths. Since NSMs are
sharable, if f2 enters the network, it also has access to either NSM according to the specific service requirement.
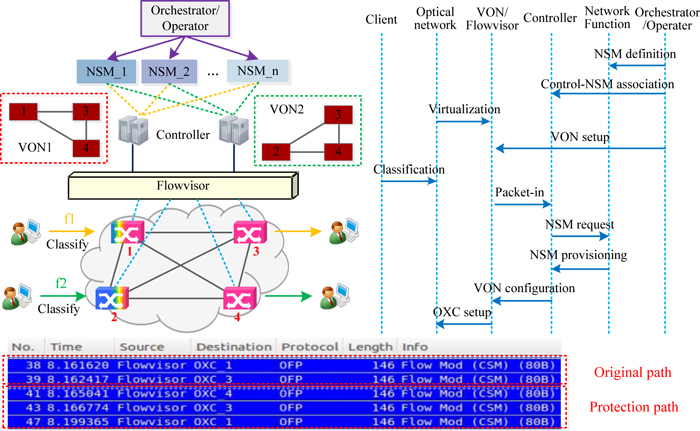
Fig.1 SDN-based elastic network service provisioning in virtual optical network
This work is partially supported by Ministry of Internal Affairs and Communications (MIC) "STRAUSS", Japan.
References:
- A. Pages, et al, "Virtual network embedding in optical infrastructures," 14th ICTON, 2012.
- http://www.opennetworking.org/, [Online], "The Open networking foundation homepage for SDN and Openflow".
- W. John, et al., "Research directions in network service chaining," SDN4FNS, 2013.
- R. Sherwood et al., "Can the production network be the testbed?" USENIX OSDI, 2010.
![]()
Biography:
Xiaoyuan Cao received his Ph.D. degree in Communication and Information System from Beijing University of Posts and Telecommunications (BUPT), Beijing, China, in 2012. From 2010 to 2011, he was a visiting scholar at State University of New York at Buffalo, USA. From 2012 to 2013, he was working for State Grid Corporation of China, Beijing, China. Since Sep. 2013, he has been with KDDI R&D Laboratories, Inc., Saitama, Japan. He has been engaged in researches on optical networking, software-defined networking (SDN) and network virtualization.

SDN (Software Defined Networking) is an attractive technology for unified control of transport networks.
Applications of SDN technology have been investigated and interoperability actively demonstrated [1-2]. SDN has a
variety of uses, e.g. visualization across multi-layer networks, automatic path computation, disaster recovery for
multi-domain networks, management of virtual resources, and so on. In this presentation, we focus on the management
of virtual resources. If a number of physical resources are unified in a virtual resource, the complexity of managing
optical transport equipments is removed, and reduced OPEX can be expected. If, conversely, a single physical resource
is spread across a number of virtual resources, reduced CAPEX, this time of the network equipment, can be expected.
There are two problems managing virtual resources. The first is defining the interface between an orchestrator
controlling the entire network and the SDN controllers controlling the transport network. The management objectives
differ between carriers and users, for example a carrier manages the network resources at optical layer, whereas users
manage the UNI ports provided by the transport network. Therefore a range of virtualization levels is required by the
different managers. Similarly, there are multiple transport network requirements. For example, there are requirements
for low latency for call services, high bandwidth for video streaming services, fault tolerance for communication
maintenance, and so on. However transport networks do not have a standardized interface for configuring these
different virtualizations. The second problem is the agility of allocating virtual resources. If the orchestrator requests
network resources for a number of paths, then a large amount of computation occurs in the process of allocating the
appropriate physical resources. However it is necessary to complete this computation quickly in order to provide a
useful service.
To solve the above problems we propose the following solutions. The first is to define the interface between the
orchestrator and the EMS. As shown in Fig. 1(a), the EMS receives a resource request from the orchestrator via the
REST API in the NBI, and manages the transport network as an SDN controller. The resource request includes the paths'
endpoints, the service type (low latency, high bandwidth, etc), and the virtualization level. As the virtualization level is
increased, the degree of unification of the physical resources increases, so that many of the physical resources are
hidden. The EMS computes the resources corresponding to the requirements, then responds with information on the
virtual resources based on the virtualization level requested by the orchestrator. The second solution is to implement a
resource computing function using a heuristic algorithm in the EMS which computes suboptimal resources for the paths
requested by the orchestrator. The resource computation sequence is shown in Fig. 1(b). The EMS receives a resource
request from the orchestrator, then the resource computing block computes physical resources based on information on
the network topology, the state of the paths and the requirements, e.g. minimizing delay time, maximizing bandwidth, or
minimizing the number of 3R regenerator. After that, the resource computing block manages the mapping between the
physical and virtual resources, and the NBI termination block responds with a resource response message.
In this presentation we discuss the design and implementation of the interfaces and the allocation of virtual
resources.
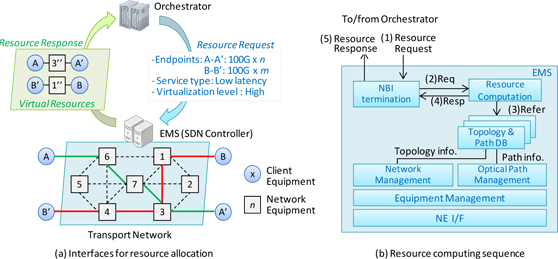
Fig.1 Proposed interfaces and resource computing sequence
References:
- Optical Internetworking Forum, "Transport SDN Prototype Demonstration", http://www.oiforum.com/public/Transport_SDN_Prototype_Demo.html, 2014.
- Xiaoyuan Cao, "SDN/OpenFlow-based Unified Control of 100 Gb/s-Class Core/Metro/Access Optical Networks," SDN/MPLS2014, Washington, DC, USA, Nov. 2014.
![]()
Biography:
Masaki Tanaka received B.E. and M.E. degrees from Chiba University, Chiba, Japan, in 2000 and 2002, respectively. He has been working at Mitsubishi Electric as researcher since 2002. His research interests include software defined networking, network virtualization, management architecture of optical network, and media access control of passive optical network.

This paper presents a centralized impairment-aware routing and regenerator allocation (IA-RWA-RA) algorithm to be deployed in a SDN controller for optical networks. The IA-RWA problem is considered as two sub-problems, one is optimal regenerator assignment in impairment-aware reachable virtue topology which defined as Optical Reachablity Graph(ORG) in algorithm and another is physical path mapping with minimum cost. The ORG represents the optical reachability by considering physical impairments accumulations between node pairs. Each link in the reachable virtue topology corresponds one or more optically feasible paths in the lower layer topology. A heuristic routing algorithm which assigns better and fewer regenerators to reduce the cost for each demand while the aim of success ratio is promised. The physical path mapping algorithm is not only consider physical impairment but also consider loop free constraint which means the optical path cannot cross one node more than twice. There are six steps in the proposed algorithm, such as follow:
- Step1: Constructing Demand Reachable Graph(DRG) for each demand by modifying ORG. Each DRG is consist of all feasible generator routes .
- Step2: Calculating all candidate routes crossed less than three regenerators on each DRG.
- Step3: Optimizing regenerators assignment for demands according the routes found in step2. We proposed a heuristic algorithm which mainly combines Max-flow and Max-matching. And the algorithm objective is maximize number of demands which assigns regenerator route successfully and minimize regenerator usage.
- Step4: Constructing Physical Mapping Graph(PMG) which can reflect the reachable physical paths information of regenerator route effectively for each demand according to the 3R route calculated in Step3. Then calculate the minimal cost physical path which should meet route policies and loop free constraint.
- Step5: Assigning wavelength for demands which mapping succeeded in Step4.
- Step6: Calling reroute and iterative optimization processes for failed routed demands.
To evaluate the algorithm's performance, we selected two real world network topologies and created six demand matrices for each topology, making up a total of 12 test datasets. The first network topology has 21 ROADM nodes and 33 OMS links, and the second network topology has 55 ROADM nodes and 90 OMS links. The CSPF algorithm described in [2] is used as the benchmark.
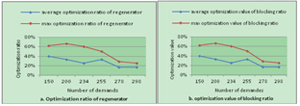
|

|
| Fig.1 Optimization of regenerator usage blocking ratio in middle topo | Fig.2 Optimization of regenerator usage blocking ratio in small topo |
The Fig.1 (a) and Fig.2 (a) show that proposed algorithm's average of regenerator usage (a) optimization ratio is reduced by 10%, compared with CSPF.
And IA-RWA-RA's max regenerator usage optimization ratio block is 30% lower than CSPF.
The Fig.1 (b) and Fig.2 (b) show that proposed algorithm's average of routing blocking ratio is reduced by 10%, compared with CSPF.
The max difference of CSPF and IA-RWA-RA blocking ratio is 50%.
![]()
Biography:
LinTan, received the master degree from the Beijing University of Post and Telecommunication, majoring in Electromagnetic field and microwave technology. She is working in Advanced research department and focus on network plan and Optical networks currently.

Traffic engineering (TE) to dynamically control traffic routes to accommodate traffic with limited network resources has
become important for Internet service providers to efficiently use network resources. Current TE techniques use coarsegrained
traffic, such as origin-destination (OD) flows, as a granularity of routing control, and such techniques enable
only rough control of traffic. On the other hand, quality of experience (QoE) has been a key performance indicator of
networks. Controlling traffic according to its characteristics, such as service classes or traffic patterns, is promising for
QoE improvement. For example, carrying predictable traffic through the shortest paths can improve network efficiency, or
distributing unpredictable traffic, such as spike traffic, into multiple paths, can prevent their concentration into a specific
link; thereby, improving network robustness. New networking technologies to control fine-grained traffic, such as 5-tuple
microflow, SDN/OpenFlow, have received much attention in recent years. Although such technologies enable fine-grained
flow control, controlling all 5-tuple microflows is impractical regarding the space constraint of flow table.
We propose a macroflow-based TE scheme in a SDN-controlled network. A macroflow is a flow group consisting of
a number of flows having common traffic characteristics and is expressed by any combination of 5-tuples that allow
wildcards. Our proposed TE scheme uses medium-grained traffic, namely macroflow, as a granularity of routing control
within limited flow table space. Our macroflow-based TE scheme can change the control policies of each macroflow
according to its traffic characteristics. Specifically, our scheme changes the routing parameter according to its predictability
measured using the coefficient of variation of time-series traffic volume. This routing parameter determines the balance
between network efficiency and network robustness. To enable macroflow-based TE on a general OpenFlow switch, we
need to generate flow tables to express macroflows within limited flow table space. To simplify and compress flow table
space, we generate three types of flow tables and arrange them hierarchically; OD, macroflow, and multipath (Fig. 1).
In the first flow table, flows are separated according to the MPLS label to identify an OD pair of a flow. MPLS labels
have been attached to flows at the ingress router in advance. Next, flows are aggregated into macroflows according to
their characteristics, which in this case, is the coefficient of variation of time-series traffic volume. Finally, flows are split
into multiple output ports based on the hash value of their flow header. Simulation evaluation results suggest that our
macroflow-based TE scheme can reduce the maximum link load in a network at the most congested time by 34% and
the average link load in a network by 11% on average compared to the current TE scheme.
To demonstrate the feasibility of our macroflow-based TE scheme, we constructed a proof-of-concept (PoC) network
making use of open-source software. Our PoC network consists of nine physical machines installed with Open vSwitch,
an OpenDayLight controller server, and TE server. Our PoC network emulates the Internet2's topology data and flow
data. The TE server, which is a key component of our PoC network, has two important functions: macroflow generation
and route optimization. We developed a macroflow-generating algorithm within limited flow space using metaheuristics
approaches [1] and a route optimization algorithm to control unpredictable traffic using model predictive control [2]. TE
server also visualizes the effect of TE through a Kibana web interface [3].
Acknowledgment:
This work was supported in part by the Strategic Information and Communications R&D Promotion Programme
(SCOPE) of the Ministry of Internal Affairs and Communications, Japan.
References:
- Yousuke Takahashi, Keisuke Ishibashi, Noriaki Kamiyama, Kohei Shiomoto, Tatsuya Otoshi, Yuichi Ohsita, Masayuki Murata. "A Generating Method of Macroow for Flow-based Routing," Technical Report of IEICE(IA2013-84). (in Japanese).
- Tatsuya Otoshi, Yuichi Ohsita, Masayuki Murata, Yousuke Takahashi, Keisuke Ishibashi, Kohei Shiomoto and Tomoaki Hashimoto. "Traffic Engineering Based on Stochastic Model Predictive Control for Uncertain Traffic Change," submitted to IFIP/IEEE ManFI 2015.
- "Kibana," http://www.elasticsearch.org/overview/kibana/
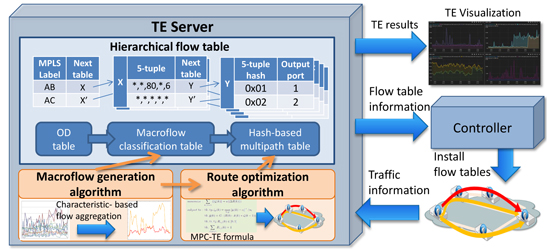
Fig.1 Overview of macroflow-based TE architecture
![]()
Biography:
Yousuke Takahashi received his B.S. and M.S. in information science from Osaka University in 2007 and 2009. He joined NTT Laboratories in 2009 and has been engaged in researches on network management and traffic engineering.

To accommodate the rapid traffic growth and service agility, network needs to be more open, pplicationcentric and programmable.
In this session, we would like to explore the applicability of Segment Routing [1] as an approach for SDN.
Segment Routing enables explicit or loose source routing, like RSVP-TE, but without such additional control plane.
This avoids overloading the distributed control plane.
Instead, it facilitates to logically centralize the intelligence that makes more sense if centralized.
For example, such conducts as global optimization based on traffic analytic and policy, dynamic path placement to cope with security incidents,
and so on, would be better performed by logically centralized intelligence.
First, we'll discuss how the "imperative" versus "declarative" discussion in programming paradigm also applicable to the network programmability,
and show that "declarative" approach is more suitable in terms of the robustness and the scalability,
in the distributed and complex environment.
We will then discuss about various path placement mechanisms using Segment Routing (Figure 1).
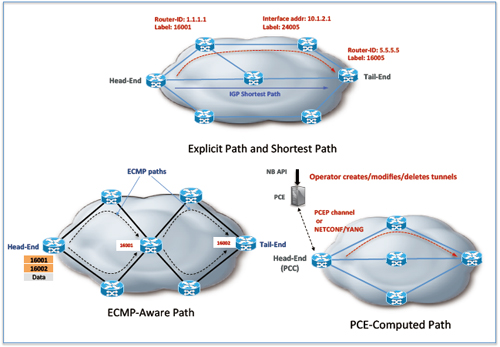
Fig.1 Segment Routing Path Placement
As for the path placement method, PCEP and/or NETCONF-YANG can be used.
Some use cases including congestion mitigation, latency-based routing and automated optimization will also be discussed.
In addition, intelligent workload placement mechanism for NFV will be discussed as an extended application of Segment Routing based SDN (Figure 2).
The mechanism would help the operators to place the NFV workload among the multiple distributed Data Centers, based on the DC resource usage and
the status of network, so that required SLA could be delivered and DC resource and Network resource could be optimized.
Lastly, we will conclude the discussion with recapitulating the usability of Segment Routing,
and its positioning as a SDN approach, particularly as a declarative network programming method.
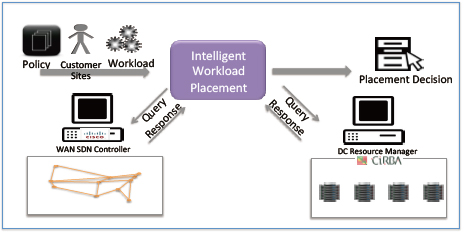
Fig.2 Intelligent Workplace Placement
![]()
Biography:
Miya Kohno is Principal Systems Engineer, Cisco Systems. Miya Kohno has started her carrier as a software developer. After joining Cisco, she has been leading architectural design and architectural transition especially in Service Provider area of business. She expertizes in IP/MPLS, BGP, Virtualization, Model Driven Architecture and Mobility. She holds M.S. from Keio University. She is a member of IEEE, IPSJ, IEICE and an SMC (Senior Mobile Consultant) of MCPC.

One of the big challenges in transport SDN is service design in multi-layer/-domain networks. PCE (Path Computation Element) is a brain of SDN controllers.
SDN controller consults its PCE to interpret service demands from network clients as paths to be instantiated, modified, or deleted in the network. PCE may
be utilized to find path candidates or to determine the exact paths to touch [1–3]. Inter-Layer PCE [4] and hierarchical PCE [5] are possible architecture
candidates for multi-layer/-domain path computation. These architectures employ on-demand queries to find and establish paths in lower or neighbor domains.
PCE authorized to initiate a path computation or provisioning queries logical TE links to child- or peer-PCEs. The first PCE does not know about the detail inside
other layers or domains, as illustrated in Fig. 1. Therefore, it is not guaranteed that the path computation or provisioning will be accomplished; in cases of failures
on the way, they must roll back the incomplete paths. This design is adopted in order to secure the scalability of data exchange and confidentiality of each domain
with the MPLS/GMPLS distributed control plane.
In this presentation, I introduce a resource-aware path provisioning mechanism for multi-layer/-domain transport SDN [6] from the perspective of PCE. In this mechanism,
the restrictions of the scalability and confidentiality are relaxed thanks to the centralized control. This relaxation allows delivering the information of potential links, which
are logical entities to indicate corresponding links are ready to serve, to PCEs of client layers or other domains in advance. Client PCEs append received potential links to
their network topologies and perform path computations on the decorated topologies (Fig. 2). Since client PCEs have the knowledge of available links in advance, end-to-end
path computations are completed by only the client PCEs. It also assures the establishment of computed paths including potential links. In addition, this mechanism provides
server layers or domains to optimize the resource utilization by computing potential links for multiple clients at a time.
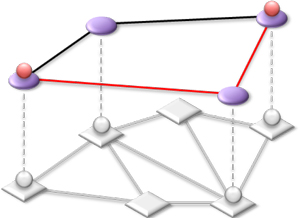
|
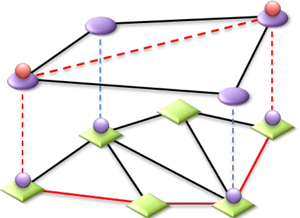 |
| Fig.1 Conventional path computation | Fig.2 Path computation with potential links |
References:
- A. Farrel, J.-P. Vassour, and J. Ash, "A Path Computation Element (PCE)-Based Architecture," RFC 4655, Aug. 2006.
- E. Crabbe, I. Minei, J. Medved, and R. Varga, "PCEP Extensions for Stateful PCE," draft-ietf-pce-stateful-pce-10, Oct. 2014.
- E. Crabbe, I. Minei, S. SIvabalan, and R. Varga, "PCEP Extensions for PCE-initiated LSP Setup in a Stateful PCE Model," draft-ietf-pce-pcep-initiated-lsp-02, Dec. 2014.
- E. Oki, T. Takeda, JL. Le Roux, and A. Farrel, "Framework for PCE-Based Inter-Layer MPLS and GMPLS Traffic Engineering," RFC 5623, Sept. 2009.
- D. King and A. Farrel, "The Application of the Path Computation Element Architecture to the Determination of a Sequence of Domains in MPLS and GMPLS," RFC 6805, Nov. 2012.
- Y. Iizawa, M. Morimoto, T. Koide, Y. Ashida, and H. Shimonishi, "Network Abstraction and Control Modeling for Hierarchical SDN Controllers," ONS 2014, Mar. 2014.
![]()
Biography:
Shinya Ishida joined NEC Corporation in 2007 and has been working for R&D on multi-layer transport network control, including PCE and GMPLS, and design. His current interests include multi-layer network design, transport SDN and stateful PCE. He received his Ph.D. in Information Science and Technology from Osaka University, Japan in 2007.

Today’s networks are going through a major transformation with the introduction of SDN/NFV. This new transformation promises to offer benefits such as service agility, enhanced visibility, greater flexibility and technology/product independence to the network operators. While the benefits are encouraging, but it is important to measure the impact of this network transformation to the end user and measure those benefits objectively. For example, when a user requests a service and later requests an on-demand bandwidth increment, with intent to improve application performance, what is the latency before the user experiences better service quality. It is important to benchmark the impact of each component in the service delivery infrastructure in terms of deployment delay, performance, jitter and loss, which may have impact of user applications. This benchmark may allow network operators and businesses to validate the true SLA for the user applications. The applicability of such performance may be seen in multi-tenant data centers. This presentation will survey the end-to-end SDN based service deployment architecture and its components and will discuss the impact of these components on the SLA KPIs. New test methodologies will be presented to validate the various components including (but not limited to) SDN orchestration. The presentation will conclude with the test results from a real-world use case.
![]()
Biography:
Aniket Khosla is a Director of Product Management at Ixia and is responsible for the Platform business unit. He is responsible for Ixia's virtual and hardware platform strategy and in his role, he manages the Ixia core test products with a focus on transformative technologies like Virtualization, 100GE , SDN and NFV . Prior to Ixia, Aniket was an engineer at Windriver systems where he helped develop protocol stacks for the VxWorks operating system. Aniket has over 15 years of experience in the networking industry and his professional experience includes roles in network engineering and marketing at Ixia. Aniket holds a Masters degree in Computer Networking from the University of Southern California, Los Angeles.

An exciting shift is happening in carrier and enterprise networking, with virtualization and software-defined networking technologies bringing new possibilities. Spirent's SDN and NFV test solutions let you build a next-generation network quickly, efficiently and with total confidence.
![]()
Biography:
Alick Luo is the Manager of Sales Development for Cloud & IP BU business development across AsiaPac, Spirent Communications, responsibility for the flagship product Spirent TestCenter promotion and business development in APAC region with rich experience on telecommunications testing and also Service Provider large scale testing, supporting CNGI, involved in Core Router testing, SR testing, and switch testing for China Telecom, China Unicom and China Mobile. A telecommunications veteran for twenty years, Mr. Luo has worked on many of overall network construction including Electronic Funds Transfer system of PBC, China Customs global network,MAN of Guangdong Telecom using a variety of technologies including Data Center, Cloud Computing, SDN/OpenFlow, X.25, Frame Relay, ATM, IP and MPLS. Mr. Luo graduated from Tsinghua University, and hold a bachelor’s degree in Electrical Engineering. He got the CCIE certification and CCIE# is 3779.

![]()
Biography:
William Wu joined Cyan Inc, since 2012, having worked for the APAC regional customer since early stage. He designed the architecture and solution for large scale telco, data center, OTT customers. He had the design and hands on experience across multiple segment of carrier infrastructure network, including optical networking, L1, L2 backbone, integrated with L3 carrier routing, flow based L4 routing, mobile fronthaul and backhaul, metro and mobile EPC network. At present he is the APAC regional system engineer supporting telco, carrier, data center customer network infrastructure and solution design.

Two years has almost passed since the O3 (O-three) project was launched by NEC Corporation, Nippon Telegraph and Telephone Corporation, NTT Communications Corporation, Fujitsu Limited and Hitachi, Ltd. This world-first research and development (R&D) project seeks to make a variety of wide area network elements compatible with SDN, including platforms for comprehensively integrating and managing multiple types of wide area network infrastructure and applications. Also, we have publicly disclosed our achievements we had so far through O3 project website. This presentation will discuss not only introduction of our project but also key benefits by using our achievement, OSS (Open Source Software) and operation guideline. The OSS for SDN framework (ODENOS), software switch (Lagopus), optical and packet control, and operation guideline.
![]()
Biography:
Yoshiaki Kiriha is a senior principal researcher in the Cloud System Research Laboratories, NEC Corporation. He received a MS degree in Electrical Engineering from Waseda University in 1987. He then joined NEC, where he has worked in the R&D division for over 20 years. He has been involved in many projects in NEC and has transferred core technologies to the product division. His research interests include distributed database systems, real-time systems, as well as future internet service and management. He has continuously contributed as a TPC for most of all IM/NOMS/DSOM conferences from 2000, and has served as a technical co-chair in NOMS 2010. Also he has served as a chair of TC on Information Communication Management, IEICE 2010-2011.

Telecoms are the industry most inclined to adopt DevOps, according to survey data from CA Technologies. But Gartner reports that there is still confusion about what DevOps is and how to put it into practice. This session will give a state of carrier DevOps update, explore what DevOps orchestration looks like and the steps to build a cloud-enabled, orchestration foundation for DevOps.
![]()
Biography:
Alex Henthorn-Iwane joined QualiSystems in February, 2013 and is responsible for worldwide marketing and public relations. Alex's career has focused on bringing emerging technologies, solutions and standards to market. He is the author of many articles in trade and technical journals and is a frequent speaker at trade and technical conferences around the world. Before joining QualiSystems, Alex was Vice-President of Marketing and Product Management at Packet Design, a provider of network management software founded by well-known serial entrepreneur Judy Estrin, and has 20+ years of experience in senior management, marketing and technical roles at networking and security startups. Alex holds a Bachelor of Arts degree from U.C. Berkeley.
Tuesday 21, April 2015

Biography:
Yukio Ito joined Nippon Telegraph and Telephone Public Corporation after graduating graduate school, having previously worked for the Switching System of PSTN and the Business Communication Network.
After the reorganization of NTT in 1999, he designed the architecture of the Transport Network of NTT Communications and introduced new technology in the Transport Network of NTT Communications. After June 2010, he had been in charge of engineering, construction and operation of the IP & L1, L2 backbone network in NTT Communications. He was in charge of the entire NTT Communications service infrastructure and was introducing SDN-OpenFlow technologies into NTT communications' Business Network.
Since August 2014, he is responsible for Technology Development to strengthen cross-service technological development capability in accordance with NTT Communications'-wide business strategies.
Since December 2011, he has been a member of the Board of Open Networking Foundation and since May 2013, he has been Chairman Okinawa Open Laboratory, a general incorporated association.

A multilayer network planning solution is developed to coordinate individual layers for better resource utilization and time efficiency.
It targets to address the existing difficulties on current planning methodology, including but not limited to:
excessive iterations between single layer planning steps; need for manual intervention; frequent design failures due to stringent
cross-layer constraints; low computation efficiency; and higher network cost.
The advantages of the new planning solution are built on:
(a) the cost reduction from optical bypass and multilayer coordinated grooming;
(b) reoptimization on IP topology;
(c) the better near optimal solutions comparing to the existing manual iterative method;
(d) supporting the design of flexible VLAN sub-interfaces;
(e) improved network reliability via protection coordinaprotection across layers, survivable IP topology planning, SRLG auto-generation & mapping, and traffic classification based on delay, failure
tolerance, and protection type; and (f) enhanced multi-layer planning and operation efficiency.
The solution contains five steps:
(1) Plan IP topology with minimum cost based on input traffic matrix and site information;
(2) Deploy IP links on the optical topology to meet survivability needs across layers;
(3) Compute traffic routes to meet SLA and protection needs, and allocate the corresponding capacity;
(4) Plan virtual IP links and reserve its redundant protection ports and optical resource;
(5) Perform failure simulation and what-if analysis. This planning solution also supports following features:
(i) Minimum cost planning for IP topology and survivable topology mapping so that the cost of all IP ports are minimized while IP topology is resilient to any single fiber cut.
(ii) Physical interface and VLAN sub-interface planning for automatic traffic off-loading, and multilayer traffic grooming at ODUflex's 1.25Gbps fine granularity
in order to achieve confined bandwidth fragmentation, differentiated traffic protection grade, and IP and optical port count reduction.
(iii)SLA-based class of service planning, i.e., considering various service latency and 50ms switch-over time upon failures.
(iv) Multilayer coordinated planning for high Quality-of-Protection(QoP). It uses TE-FRR and optical 1:1 to achieve dual failure protection.
It also supports protection group of IP links with common-source different-destination to defend triple failures in some extreme cases.
Several real networks are used for the numerical study in the multilayer planning solution.
Fig.1 shows the cost reduction of 15-40% using this new solution than the existing iterative method.
This gap becomes larger on bigger networks.
On the same networks, higher traffic volume could also produce larger cost reduction gap.
Among many other results, a interesting one is that the VLAN-aware planning could achieve the cost reduction at 20-31% than the planning using
the physical port alone. All these results illustrate the benefits of the presented multilayer planning solution.
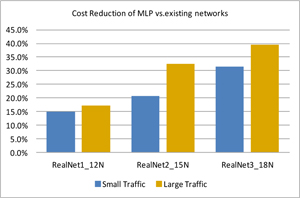
Fig.1 Cost Reduction from Multilayer Planning Solutions
![]()
Biography:
Zhicheng Sui received his Phd degree in EE from State Key laboratory of Advanced Optical communication systems & networks, Shanghai Jiaotong University. He joined Huawei network research department in 2006 and specialized in network planning and optimization algorithm research & development for OTN/WDM, Microwave, IP and IP over OTN networks.

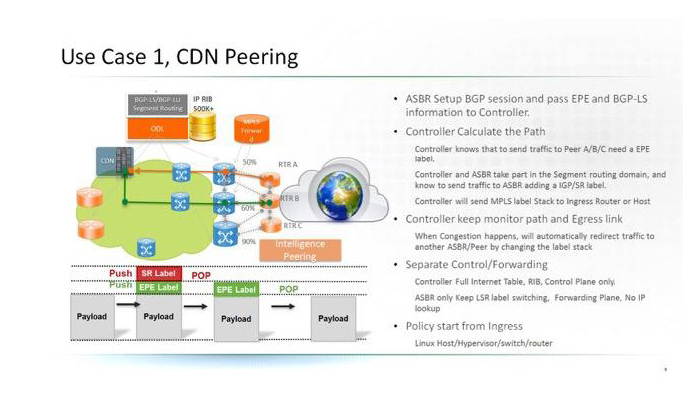
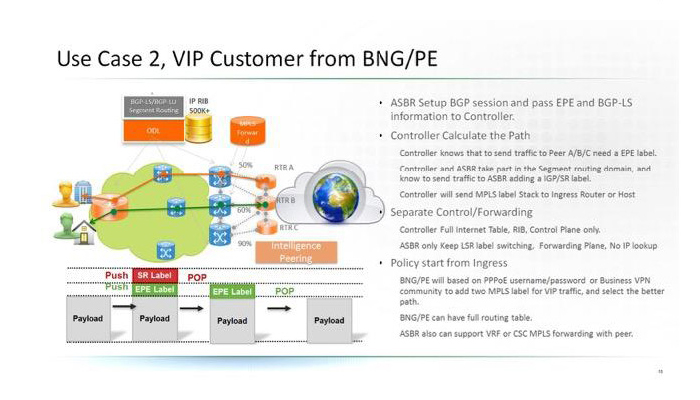
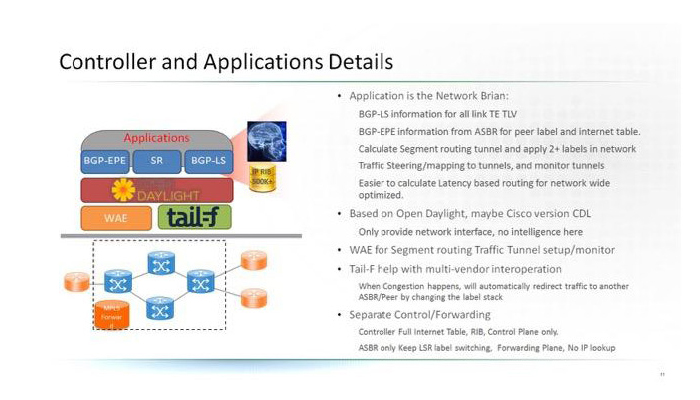
Please check our Cloud Peering solution which will benefit Web/OTT and SP customers with new optimised network architecture.
Also this solution extended Traffic engineer to inter-AS/BGP Peering, and provide network wide
optimisation to intra domain and Cloud Peering.
The new Solution leverage the latest progress on Segment Routing/ BGP egress Peering.
And remove the IP lookup on ASBR, leverage LSR routing in Peering.
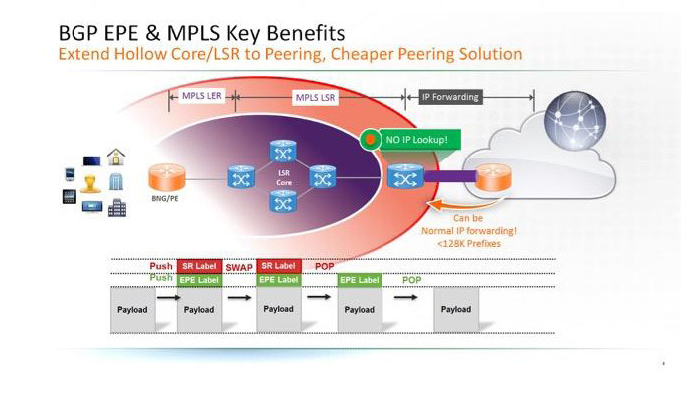
Please check two use case for Web/OTT CDN and SP residential/busienss VIP customers.
![]()
Biography:
Shaowen Ma is a Sr. Product Manager in Cisco SP routing business unit. He currently focus on SDN/NFV Solution/Product define/design for Cloud and SP network. He is also reasonable Key SP/Web/OTT Customer engagement in APAC & worldwide. He graduated from Harbin Institute of Technology, China in 1999 with master degree of Since, Control Engineering.

Control Planes and SDN provide similar benefits to networks. Both solutions strive to enable end-to-end service provisioning,
network level protection, automated behavior, some multi-layer coordination, and in SDN's case the ability to easily customize
network behavior with applications. However, while these capabilities are both powerful and flexible, they will always be limited
by the actual capabilities of the network they are attempting to control. Even the most powerful and feature rich control plane or
SDN controller will not provide much value to a transport network designed with fixed filters and transponders.
A network such as that is incapable of being modified without human interaction.
As progress is made on making control planes and SDN controller more powerful, it is equally important to focus on the underlying
architecture that these solutions are controlling. This presentation will examine traditional networking architectures including circuit
based (SONET/SDH/OTN), packet based (CE/MPLS-TP/IP), and various optical layer technologies (ROADM/Colourless/Directionless/Contentionaless)
and dissect the pros and cons of these architectures as they related to their synergies with the dynamic control mechanisms provided by control planes and SDN controllers.
Next, Coriant will highlight as interesting approach to building transport network equipment that can more effectively be leveraged by
control planes and SDN controllers to provide a definitively more flexible and adaptable complete networking solution called Universal
Transport Platforms. Universal Transport Platforms - such as the Coriant mTeraTM Universal Transport Platform - are
capable of switching traffic at any layer on every port and can switch multiple layers at the same time on every port. Universal Transport
Platforms groom traffic frame by frame and can unpack incoming frames all the way down to the IP layer. While this capability provides
inherent benefits to flexibility, efficiency, and adaptability via traditional network management mechanisms, it is particularly powerful when
used in conjunction with the more dynamic control mechanisms provided by control planes and SDN controllers.
Finally, Coriant will focus on one of the most interesting applications of a network built based on Universal Transport Platforms is when used
in conjunction with an SDN controller. While the Universal Transport Platform can read the ip header information, to be cost optimized, they
generally will not be running complex ip networking protocols. Hence - they would not be capable of providing any type of routing functionality
on their own. However, SDN controllers are capable of running those network protocols and in turn instruct the Universal Transport Platforms
how to handle incoming ip traffic streams. Working together - SDN controller and Universal Transport Networks would be capable handling a
not insignificant share of the network routing requirements. It is this promise - the combination of truly Universal Transport Networks built with
products such as the Coriant mTera and a Dynamic SDN solution such as the Coriant Transcend SDN solution that can provide a new level of
networking capabilities that provide the foundation for the Coriant Dynamic Optical CloudTM.
![]()
Biography:
Rob Shore is the director of product marketing for Coriant. In this role, he is responsible for working closely with Coriant's technical strategy team and sales organization to develop collateral and messaging that promote Coriant's product portfolio and networking solutions.
Prior to his current role in marketing, Rob was working in Coriant's technical sales organization managing the Solution Sales Management team for the Europe, Middle East, and Africa regions. He has also held positions in the North America sales organization, market management, segment marketing, tier 3 technical support, product development and solution validation at Coriant.
Rob has more than 20 years of experience in the telecommunications industry. He holds a Bachelor of Science degree in electrical engineering from the University of Illinois. He is also a certified master of PowerPoint and currently holds the (unconfirmed) world record for most number of animations on a single slide.

Shortly after the iPoP 2015 meeting we expect that the BBF will send to final ballot an implementation agreement entitled
"Achieving Packet Network Optimization using DWDM Interfaces". This work began in another Japanese city, Osaka, over two
years ago. Two years later, in Naha, we think it worth examining that work to see what lessons can be learned from it.
First we examine what network optimization might mean and what, specifically, it means in the context of the BBF work.
We explain the interfaces and the data, control and management planes involved in the proposed solution. We examine the rates at
which the technologies associated with those various components are changing.
The BBF work has been complicated by dependencies on other SDOs, ITU-T and IETF, that own the definition of various aspects of
the proposed solution. We examine those in some depth and, in particular, attempt to shed some light on the black link methodology
of the ITU-T. We examine the challenges associated with such cross organizational efforts and draw some lessons from them.
In the two years between the project's commencement in Osaka and our meeting here today we recognize that much has changed in the
network industry; iPOP itself is focused heavily on SDN and we consider whether that technology has direct applicability to the
network optimization goals the project was intended to address. We claim the answer is that it does.
Finally we draw this material together to make some observations on the standards process in general, this project in particular and
the likely evolution of solutions of this type.
We ask is the proposed solution "too little too late or just enough in time". Our conclusions are mixed but, in a spirit of optimism,
we make some predictions with respect to adoption timelines and some recommendations for further work.
We think this presentation will be useful to those who have specific interest in the employing colored interfaces in packet devices
and to those who are students of the, sometimes less than perfect, process of developing standards in general.
The presenter is a co-editor of the BBF work examined here and active in related activities in the ITU-T and IETF.
![]()
Biography:
Paul Doolan works in the CTO office at Coriant where he directs the company's standardization activities. He contributes personally in ITU-T, BBF, ONF and IETF. Paul is a joint editor, with Fang Li of CATR, of the ITU-T SG15's G.asdtn Architecture for SDN control of transport networks. In the SDN arena he is chair of the ONF's Carrier Grade SDN project.
Wednesday 22, April 2015

The annual global data center (DC) IP traffic is expected to reach 6.6 zettabytes by
the end of 2016 at a compound annual growth rate (CAGR) of 31 % from 2011 to
2016 [1]. Current intra-DC network communication, which is still based on high
capacity electrical switches, is facing technical challenges of high power
consumption and high latency. An energy-efficient and low-latency intra-DC
network has been proposed [2]. The network is based on optical packet switching
(OPS), and consists of hybrid optoelectronic packet routers (HOPRs). HOPR uses an
electrical shared buffer which consumes a large part of the total power of HOPR.
Therefore, we have proposed a buffer management scheme to further reduce the
power consumption in the intra-DC network [3]. The scheme shuts off the shared
buffer of HOPRs by aggregating virtual machines (VMs) on one side. HOPR can
transit packets even if the shared buffer is shut off. In the current intra-DC network,
the packet cannot transit when the electrical buffer in a switch is shut off. Therefore,
HOPR-based DC can aggregate VMs flexibly in low network power consumption
because packets generated by VM aggregation are transferred flexibly on
HOPR-based DC network. We have to consider DC performance with buffer
management realizing low network power consumption. Excessive power reduction
of HOPRs probably affects DC performance due to heavy load on some servers
under HOPR. Therefore, we need to consider a balance between power reduction in
the DC network and DC performance in order to achieve high performance in DC
under low network power consumption with buffer management.
In this presentation, we study on relationship between DC performance and
network power consumption with buffer management in HOPR-based DC by
simulation in order to show how the buffer management scheme affects DC
performance. We consider a simulation model that changes aggregation ratio of
VMs and operation rate of VMs in some topology models in order to confirm the
buffer management scheme under various DC circumstances. The aggregation ratio
of VM is based on the number of operated VMs in a physical machine. We reveal a
control principle of buffer management scheme in HOPR-based DC from the
simulation to realize high performance in DC under low network power
consumption.
Acknowledgement:
This work is a part of "Research & Development of Basic Technologies for High
Performance Opto-electronic Hybrid Packet Router" supported by National
Institute of Information and Communications Technology (NICT).
References:
- Cisco Global Cloud Index: Forecast and Methodology, 2011-2016.
- R. Takahashi et al., "Recent progress on hybrid optoelectronic router for future energy-efficient optical packet switched networks," PS2012, Corsica, France, Sept. 2012.
- K. Kitayama, et al., "Optical packet and path switching intra-data center network: Enabling technologies and network performance with intelligent flow control," ECOC2014, Cannes, France, Sept. 2014.
![]()
Biography:
Masahiro Hayashitani received the B.E. and M.E. degrees in information and computer science from Keio University in 2005 and 2007, respectively. He is currently with Cloud System Research Laboratories, NEC Corporation. He is engaged in SDN technology for carrier networks and data centers.

As the data centers are facing significant increase in both scale and bandwidth demands, various optical circuit switching architectures
have been proposed to handle the "elephant flows" between top-of-rack (ToR) switches within data center networks [1-2]. Typically,
traffic within a data center have skewed communication patterns that in a moment only a small number of ToR switches are hot and
sending "elephant flows" to their partners [3]. Hence, it is not efficient to equip one optical transmitter for every ToR switch in the
intra-data center optical circuit switching architectures.
We present a virtual connected transmitter scheme and design a transmitter virtual connecting infrastructure that can provide virtual
connected transmitters for a group of adjacent ToR switches. The transmitter virtual connecting infrastructure and the implementation of
virtual connected transmitter scheme in intra-data center optical circuit switching architecture are shown in Fig.1. Every n ToR switches
are connected to a transmitter virtual connecting infrastructure via a relatively cheap and low-energy n*m electrical circuit switch (n>m).
In one transmitter virtual connecting infrastructure, m physical transmitters are allocated in a transmitter resource pool that is shared by n
ToR switches using a statistical multiplexing method. When one ToR switch wants to send an "elephant flows" into the intra-data center
optical circuit switching architecture, the orchestrator will find a free transmitter in the transmitter resource pool and dynamically
configure the electrical circuit switch to connect the free transmitter with the asking ToR switch. Thus, n logical transmitters are
virtualized by m physical transmitters for the n ToR switches. It should be noted due to the transmission distance limit of electrical signal,
one transmitter virtual connecting infrastructure is only suited for ToR switches which are placed adjacently.
Apparently, there is a tradeoff between transmitter saving and traffic blocking performance in the virtual connected transmitter scheme.
Assume the "elephant flows" arrive according to a Poisson process and have independent, exponentially distributed durations, we
simulate the traffic blocking rate under different values of transmitter reuse factor. We also calculate the cost and power saving of our
transmitter virtual connecting infrastructure using the parameters of commercial available devices or products. Our results show that with
the same traffic load and the same blocking rate, larger connected ToR switch number n of the transmitter virtual connecting
infrastructure has a more transmitter saving. If we set the traffic load to be 50%, a transmitter reuse factor of about 1.4 can be achieved for
10 connected ToR switches while a transmitter reuse factor of about 2.5 can be achieved for 100 connected ToR switches to guarantee the
1% blocking rate request.
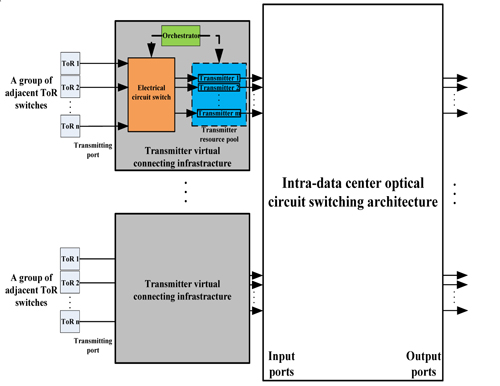
Fig.1 The transmitter virtual connecting infrastracture and the implementation of virtual connected transmitter scheme in intra-data center optical circuit switching architecture
References:
- G. Wang, D. G. Anderson, M. Kaminsky, K. Papagiannaki, T. E. Ng, M. Kozuch, and M. Ryan, "c-Through: Part-time Optics in Data Centers," in Proc. ACM SIGCOMM 2010 conference on SIGCOMM, ser. SIGCOMM' 10, 2010, pp. 327-338.
- N. Farrington, A. Forencich, G. Porter, P. C. Sun, J. E. Ford, Y. Fainman, G. C. Papen, and A. Vahdat, "A multiple microsecond optical circuit switch for data center networking," IEEE Photonics Technology Letters, vol. 25, no. 16, pp. 1589-1592, Aug. 2013.
- T. Benson, A. Anand, A. Akella, and M. Zhang, "Understanding data center traffic characteristics," in Proc. Sigcomm Workshop: Research on Enterprise Networks, 2009.
![]()
Biography:
Zitian Zhang received the B.S. degree in electronic information and electrical engineering from Shanghai Jiao Tong University in 2010. He is currently working toward the Ph.D. degree in electronic engineering at Shanghai Jiao Tong University, China. His research interests include hybrid optical/electrical switching, data center networks and flexible grid optical transport networks.

The rapid growth of mobile devices like Smartphone causes an exponential increase of mobile traffic. The
emergence of new applications like Machine-to-Machine and Internet of Things leads to the diversity of traffic
characteristics. Network operators have to manage more increasing and more diversified mobile traffic in a costefficient
manner.
To solve this problem, Network Functions Virtualization (NFV) [1] has arisen. The concept of NFV is to deploy
network functions onto industry standard servers by virtualization technology. NFV is expected to faster
introductions of new services and reduce capital expenditures and operational expenditures. The virtualization of the
mobile core network is one of main targets for NFV [2].
This presentation focuses on reliability in NFV-based virtualized Evolved Packet Core (vEPC) which
consolidates virtual nodes with mobile gateway functions. Since standard servers are generally less reliable than
dedicated devices, it is important to ensure appropriate reliability.
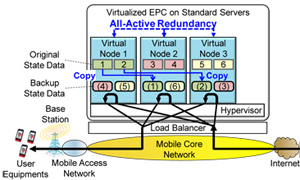
To realize reliable the vEPC, we introduce all-active redundancy shown in Figure 1. All virtual nodes are used as
active nodes, and virtual nodes store the backup state data of each other. When a virtual node failure occurs, other
virtual nodes continue the process of the faulty virtual node by using the backup state data. By replicating the state
data again, the vEPC can execute the redundancy reconfiguration. The all-active redundancy is cost-effective and
reliable, but it has the problem that a redundancy reconfiguration failure like an error of transmitting the state data
may harm all virtual nodes.
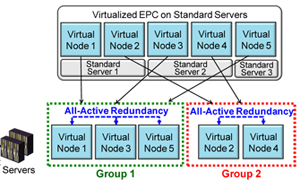
To solve this problem, we propose a new redundancy configuration scheme shown in Figure 2. The proposed
scheme divides virtual nodes into groups for the redundancy configuration. In Figure 2, the proposed scheme makes
two groups. Each group configures the all-active redundancy. By limiting the number of virtual nodes for the
redundancy configuration, the proposed scheme reduces the number of virtual nodes affected by the redundancy
reconfiguration failure.
In Japan, accidents causing the duration of communication suspension two hours or more may be regarded as
significant accidents [3]. To prevent significant accidents, we aim at the redundancy reconfiguration within one
minute with minimum negative affect on virtual nodes during the redundancy reconfiguration failure. Simulation
results show that, in the vEPC accommodating one million sessions, the proposed scheme can execute the
redundancy reconfiguration within 54 sec, and reduce the ratio of virtual nodes affected by the redundancy
reconfiguration failure to 16.7 % from 100%.
|
|
| Fig.1 All-active redundancy | Fig.2 Proposed scheme |
References:
- ETSI, "Network Functions Virtualisation – Introductory White Paper," SDN and OpenFlowWorld Congress, Darmstadt, Germany, Oct. 2012.
- H. Hawilo et al.,"NFV: state of the art, challenges, and implementation in next generation mobile networks (vEPC)," IEEE Network Magazine, vol. 28, no. 6, pp. 18-26, Nov.-Dec. 2014.
- MIC in Japan, "Guidelines on Application of Applicable Laws and Regulations etc. within the Telecommunications Business Act in Relation to Telecommunication Accidents," http://www.soumu.go.jp/main_sosiki/joho_tsusin/eng/councilreport.html, Sept. 2010.
![]()
Biography:
Daisuke Ishii joined Hitachi, Ltd., Central Research Laboratory in 2012. He has been working for research and development in mobile core network and network functions virtualization. He received his B.E., M.E. and Ph.D. degrees in Engineering from Keio University, Japan, in 2003, 2005 and 2009, respectively. From 2009 to 2011, he was a research associate at Keio University, Japan.

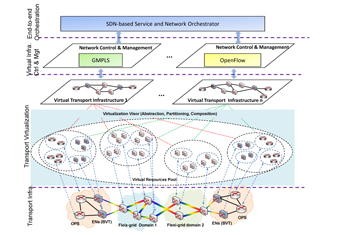
The STRAUSS project [1] proposes a future software defined optical Ethernet transport network architecture
(Fig. 1), composed of four layers: A data plane layer to support Ethernet transport beyond 100 Gb/s, combining the
high-capacity flexi-grid OCS and OPS systems; a transport network virtualization layer that virtualizes the heterogeneous
data plane resources; a Virtual Infrastructure control plane, employing GMPLS and customized network control based on
OpenFlow, that sits over each virtual transport infrastructure, providing independent control functionalities in order to handle
both covered switching technologies (i.e., OPS and flexi-grid OCS) and, finally, a Service and network orchestration layer,
using SDN-based orchestrator to enable the seamless interworking between the control planes for the automatic
provisioning of end-to-end Ethernet transport services spanning the targeted multi-layer, multi-domain network.
Most of the solutions for SDN are based on single domain and mono vendor solutions. However, network operators
usually have in place multiple technologies (provided by different vendors) in their networks and multiple domains to
cope with administrative and regional organizations. A single SDN controller cannot configure the whole network of an
operator for scalability and reliability issues. This is even more complicated when considering and architecture that should deal
with OpenFlow and GMPLS domains at the same time.
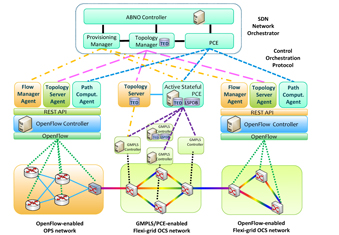
The network orchestrator follows the Application-Based Network Operations (ABNO) architecture, which is being
defined in IETF based on standard building blocks [2]. Fig. 2 presents the main four building blocks of the ABNO
architecture. The ABNO Controller runs the workflows and it can to talk with the different blocks, while the PCE computes
the paths between the different domains. The view of the PCE can be the physical network or an abstracted network.
Moreover, the PCE is able to talk with each of the PCEs in the domains to build an end-to-end path. The Topology Module is
in charge of retrieving the information of the network status. Finally, the Provisioning Manager configures the network
elements depending on the control plane technology that the device supports.
Regarding the relation between the controllers, a hierarchy of controllers is used, where there are multiple SDN controllers
interacting with a SDN orchestrator hierarchically placed on top of them. The Control Orchestration Protocol (COP)
abstracts a set of control plane functions used by an SDN Controller, allowing the interworking of heterogeneous control
plane paradigms (i.e., OpenFlow, GMPLS/PCE). Each controller requires having a method to ask for connections and
provide topological information. The users may not be able to request for paths to a SDN controller, but this functionality is
required between controllers to enable end-to-end path optimization.
|
 |
| Fig.1 STRAUSS network architecture | Fig.2 Proposed SDN network orchestration for multiple domains with heterogenous transport and control planes technologies |
Acknowledgments:
This work was supported by the European Community’s Seventh Framework Programme FP7/2007-2013 and the
Japanese Ministry of Internal Affairs and Communications (MIC) in the STRAUSS project (608528).
References:
- R. Muñoz, et al.: Network Virtualization, Control Plane and Service Orchestration of the ICT STRAUSS Project, in European Conference on Networks and Communications (EuCNC), June 2014.
- D. King, and A. Farrel, "A PCE-based Architecture for Application-based Network Operations," IETF draft, draft-farrkingel-pce-abno-architecture-11, work in progress 2015. End-to-end SDN orchestration in optical multi-technology and multi-domain scenarios
![]()
Biography:
Takehiro Tsuritani joined Kokusai Denshin Denwa (KDD) Company, Limited (currently KDDI Corporation), Tokyo, Japan in 1997. Since 1998, he has been working at their Research and Development Laboratories (currently KDDI R&D Laboratories Inc.) and has been engaged in research on high-capacity long-haul wavelength division multiplexing (WDM) transmission systems and dynamic photonic networking. Currently, he is working as a Senior Manager of Photonic Transport Network Laboratory in KDDI R&D Laboratories Inc. and a Member of IEEE and IEICE.

Scientists in campuses have a need to move large datasets. This is not an everyday occurrence, but when needed it would be most useful to have a network that supports these large dataset transfers. For example, a Biomedical Engineering Professor at UVA recently needed to move 14 TB from U. Cincinnati. Large enterprises, such as university campuses, are currently considering migration of their 10Gb/s WAN-access links to 100Gb/s links. However, the traffic on even the current 10Gbps access links is typically around 40%-50%. The increase to 100Gbps link rates is justified primarily for the data movement of large scientific datasets. However, since as mentioned above, such large dataset transfers are rare, we propose a WDM based architecture in which 40GE links from an OpenFlow Ethernet switch are terminated on WDM platforms, such as WC1 in the Customer 1 network as shown in the figure below. These Ethernet switches are in turn connected to high-performance data transfer nodes, which could be high-performance computing nodes that are retooled for file-transfer applications on the rare occasions that large datasets need to be transferred. Similarly other large enterprise customer networks could deploy WDM optical platforms but use additional wavelengths on their WAN access links only for large dataset transfers. In this architecture, the number of interfaces required at Provider Router RP1 could be limited and shared between the K customers. Using an SDN controller, a Layer-1 optical circuit can be established on a dynamic basis to connect the two switch ports from a given customer (e.g., Switch S1 of Customer 1) to the ports of a provider router, e.g., RP1. We expect this solution to consume lower power because the IP routers in customer networks can use lower-rate WAN-access links for everyday traffic (e.g., 40GE as shown in the figure), and the number of 40GE interfaces required in provider routers are also reduced. This dynamic optical network architecture, with an analytical evaluation, will be presented.
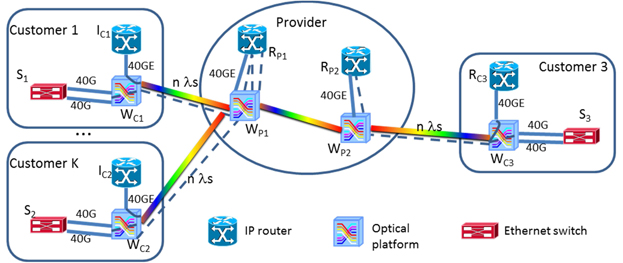
![]()
Biography:
Malathi Veeraraghavan is a Professor in the Charles L. Brown Department of Electrical & Computer Engineering at the University of Virginia (UVa). Dr. Veeraraghavan received her BTech degree from Indian Institute of Technology (Madras) in 1984, and MS and PhD degrees from Duke University in 1985 and 1988, respectively. After a ten-year career at Bell Laboratories, she served on the faculty at Polytechnic University, Brooklyn, New York from 1999-2002, where she won the Jacobs award for excellence in education in 2002. She served as Director of the Computer Engineering Program at UVa from 2003-2006. Her current research work on optical and IP networks is supported by NSF and DOE. She holds twenty-nine patents, has over 90 publications, and has received six Best-paper awards. She served as the Technical Program Committee Chair for IEEE ICC 2002, Associate Editor for the IEEE/ACM Transactions on Networking, Editor of IEEE ComSoc e-News and as an Associate Editor of the IEEE Transactions on Reliability.

The automation and optimization of network resource allocation is considered as one of the key benefits to be brought by SDN technology. This benefit can be materialized in two dimensions: First within each network layer (say IP layer), the SDN controller has the centralized network view and control, and can make automated and optimized decisions in traffic management and resource allocations for the entire network. Second between network layers, typically the IP layer and the optical layer, certain coordination can be done to synchronize and optimize resource allocation decisions between the two different layers. Our work is a study about this second dimension.
In the current industry practice, IP layer and optical layer act in isolation. Their interactions are static and managed manually through periodical planning process, where the IP organization requests transmission bandwidth from the optical organization. In recent years, more and more carriers have expressed interest in the coordination of the two layers where the interactions can be automated and optimized. IP link provisioning and cross-layer protection/restoration have been identified as key use cases. There are two SDN architectures for cross-layer coordination. In the short term, for practical reasons, the cross-layer coordination can be done by two SDN controllers, one for each layer, through limited information exchange between them. In the long term, however, it is doable that there is only one unified SDN controller that has centralized view and control for both IP and optical layers and can make optimized decisions all together. This unified controller will be more complex and therefore needs to be justified. Aside from all other considerations, a natural question to ask is how much economic savings the unified controller architecture can bring over the two-controller architecture? The aim of our work is to answer this question.
We conducted both a mathematical analysis of the two architectures and an actual testing of their performances in many representative network instances of varying sizes.
In our mathematical analysis, the comparison between unified controller vs. two-controller architectures boils down to the proper balance between IP traffic pattern driven grooming and optical topology driven grooming. Here grooming refers to the action of aggregating individual traffic flows to minimize network resource consumption. The former is an extreme strategy at optimizing IP resources and the latter is another extreme at optimizing optical resources, while the overall optimum is to strike a balance between the two (see Figure 1). The unified controller is better equipped with information about both layers to find this balance than the two separate controllers that each has only an isolated layer view and limited information exchange between layers.
Our numerical tests verified our theoretical insights. Specifically, the test results indicate that the savings of the unified controller is much more significant in the "green field" mode where many new IP links need to be added in comparison with the number of existing IP links and at the same time the optical layer resources are tight. Otherwise, (i.e., in the incremental mode where only a few IP links need to be added or when optical layer resources are not in shortage), the savings is marginal (see Figure 2).
The savings is quantified as the percentage difference in the network maximal throughputs with these two
architectures. We conclude that if IP topology and existing routing are allowed to be re-optimized, the potential savings of the unified controller will be enormous.

Fig.1 Two extremes of grooming
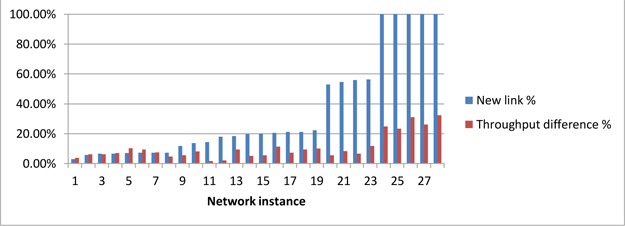
Fig.2 Network throughput difference in two architectures in relationship with percentage of new IP links
![]()
Biography:
Yufei Wang received his Ph.D. in Operations Research from Cornell University in 1992. At first he was a researcher at AT&T and Bell Labs, specialized in modeling, analysis, optimization and simulation of optical, IP and mobile networks. Later he became CTO of VPI Systems, managing research and software development for network planning and network data analytics applications. He joined Huawei in 2012, conducting network research with a focus on SDN algorithms. He has developed numerous linear/integer programming and combinatorial optimization based techniques in addressing challenging mathematical problems arising in SDN networks, such as centralized routing optimization, load balancing, dynamic congestion mitigation, joint IP+Optical optimization, and high performance parallel algorithms for large scale networks.

SDN and Network Function Virtualization (NFV) allow the IT world to control networks from a
network-centric or application-centric view. The North-Bound Interface (NBI), located between the
control plane and the applications, is essential to enable application innovations that utilize or control the
network by abstracting the network capabilities/information and opening the abstract/logical network to
applications.
NeMo is a simple Intent Based Domain Specific Language (DSL) NBI API which allows
applications the power to setup and take down virtual networks between virtual nodes. An NBI is often
provided as general APIs (standard or vendor specific) which allow detailed control of virtual network
set-up, but require detailed knowledge of the network. A majority of applications need only ~20% of the full API features and want to
signal general intent of creating a virtual network between applications on machines, rather than specific network paths between
these machines. A DSL NBI provides the 20% of features needed by most of the applications in a simple and intuitive interface. The SQL
language is a DSL for databases. The NeMo's NBI connects the application to a controller and uses 15 primitive commands to control
resources (node, link, flow), policy and controller events (policy, query, notification, connect, disconnect, transact, commit), and
modeling (node-definition, link-definition, action definition). NeMo sends these 15 commands via a RESTful interface to a
controller as Figure 1 shows. Within the controller, a NeMo Engine translates NeMo language commands to specific SDN
controller commands by combining controller information (configuration, policy, network status) and modeling information
downloaded through NeMo. NeMo's Engine can translate NeMo commands to different SDN controllers, solving the multiple SDN controller issues.
The NeMo project (www.nemo-project.net) has progressed from initial demo to creating an open source project in OPNFV.
The initial demo in October 2014 demonstrated NeMo's ability to allow applications to request virtual networks on top of a virtual network environment (Mininet
Virtual Machine on Oracle's VM virtual box) with 3 application nodes and 3 controllers as Figure 2 shows. Figure 3 shows how
NeMo's API allowed the applications to create a virtual network overlaid on this virtual network environment. Possible future
work includes standardizing the NeMo Language protocol and developing a NeMo DSL NBI for storage and computation.
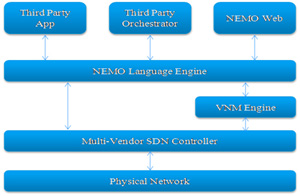
Fig.1 NeMo NBI and Engine
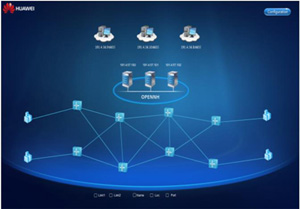
Fig.2 NeMo Demo network topology
Fig.3 Application Virtual topology overlaid on virtual network
![]()
Biography:
Susan Hares (shares@ndzh.com) has over 30 years of experience in International Standard Organizations for Internet and IT technology (IETF, IEEE, BBF, MEF, MAP/TOP) that use consensus decision making to create standards. From 1995-2007, Susan founded and was the CTO for NextHop Technologies, a company developing network hypervisor and routing/switching software suite. From 2008-2009, Susan managed a team at Green Hills Software developing routing software in a secure hypervisor that launched early version of cloud software. From 2010-2013, Susan Hares was a Senior Director of the IPBU Standards Team in the Future US R&D division of Huawei, a Chinese telecommunications company. Susan currently chairs the following IETF working groups: IDR (bgp), I2RS, and TRILL. Susan is currently a Consultant to Huawei's Beijing Research Center and a Ph.D. student at Regent University Business and Leadership School in Global Leadership.

This abstract describes the vision for an agile photonic communication infrastructure capable of supporting a range of Information and Communications Technology services offered by Tier1 operators, alternative Service providers, and research and education networking users. The envisioned solution provides virtualized connectivity resource management architecture, enabling the independent administration of each of the users allocated resources; and a fully agile and dynamic photonic network layer.
Photonic Nation is our vision for interconnecting nations and cities to support competitive ICT services enabling outsourcing of cloud computing, cloud storage and hosted software applications to cloud SPs. Photonic Nation’s applicability has a wide scope in a variety of different deployment scenario’s:
- High-speed inter Data Centre connectivity and interconnection service providers for, large enterprises and peering partners;
- On-demand and scheduled high bandwidth capacity and connectivity for massive bandwidth exchanges;
- Wholesale leased facilities to Service Providers, mobile Service Providers, content Service Providers;
- Private networks for education, for healthcare, for financial networks.
To achieve the goal of a widespread nation-wide, virtualized communication resource, the deployed solution must meet several requirements, including:
- User Independence – allowing independent turn-up and management of services and network facilities.
- Flexibility/Agility – allowing expandable and reconfigurable in order to serve varying user needs over both long-term (e.g., months) and short-term (e.g., minutes) timescales.
- Geographic Scale – to be accessible by all users and partners within the network independently.
- Scalable Bandwidth – to be able to scale in bandwidth served in order to meet the projected demands over at least the next decade.
The presentation will analyse and discuss the fundamental building blocks of the architecture, and illustrate the benefits of the architecture, these include:
- WAVE Fabric or Agile Photonic Networking - A flexible and evolvable underlying transport solution based on a photonic Wavefabric using Dense Wavelength Division Multiplexing (DWDM), augmented with photonic OAM infrastructure, in support photonic wave ping and wave trace tools.
- Digital network layer – Converged Packet-Optical Transport – enables the optimized solution based on a balance between cost, scalability, specific service needs and requirements. The usage of flex-grid enabled transponders allows the usage of supper channels, and reconfigurable encoding schemes.
- MAN/WAN SDN Controller (WSC) – enables users to operate and manage their infrastructure and complex relationships, and simplifies complex network relationships down to an intuitive topology layout that covers virtual, physical, and logical resources and relationships.
- Northbound and controller interfaces – These interfaces integrate higher-level automation solutions on top of the policy and controller framework, including workflow automation tools and analytics.
- Southbound Controller protocol – The OpenFlow protocol is typically used in SDN architecture, and vendors have released OpenFlow-compliant switches.
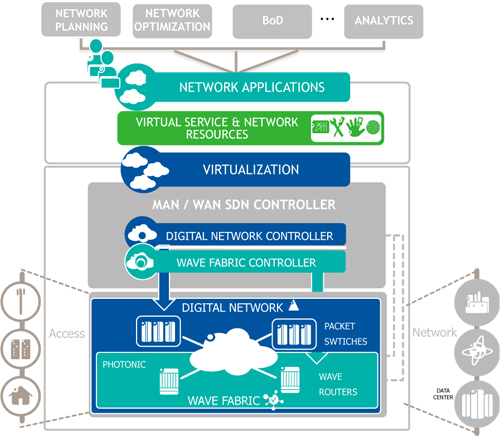
![]()
Biography:
LIEVEN LEVRAU [M] (lieven.levrau@alcatel-lucent.com) received an M. Sc. degree in Applied Physics engineering (Photonics) from the University of Brussels (VUB) in 1994 and he has studied Avionics at the University of Ghent. He has participated in several European and national research projects such as NOBEL, Dynamo and GSN. His current research interests are focused on design issues related to multi-layer network control architectures for core and metro networks, especially in network virtualization related issues, security and multi layer optical packet and transport networks for service providers and cloud providers. In his currently role as Product Line Director within the IP Transport Division, he is responsible for the IP & Optical integration, and the integration of photonics in transport networks and inter and intra data center networks. He is an IEEE member and Alcatel-Lucent Technical Academy (ALTA08) member.

Why they affect (carrier) deployment and what to do about it.
Eight years after the debut [1] of OpenFlow and four after the formation of the ONF [2] the specification of that protocol [3] remains the crowning achievement of the ONF and the singular standardized artifact of the SDN movement.
There is little doubt that, and SDN is not unique in this regard, the adoption of SDN in certain markets - most notably the telecommunications operator
market - has not matched the huge hype and anticipation that surrounded it in its public infancy.
While we will briefly touch on a number of other reasons [4] that carrier adoption has remained low we will spend most of the presentation discussing
the reasons behind the observations of Rothenberg et al [5] that "some of them (the challenges) relate to the evolving role of standardization
around SDN and the availability and readiness of northbound and southbound interface achievement".
We briefly introduce the main SDO activities in this area drawing on personal involvement and the resources in [6].
We illustrate main problem left unsolved by these various activities and the emerging notion that Open Source (OS) software is the panacea to that problem.
We examine aspects of OS in this context and contrast it with traditional SDO methodologies and work products.
Nick McKeown, one of the luminaries of the SDN movement, has frequently compared the evolution of networking equipment with that of mainframe computing
and claimed that what happened in the computer industry is a model for what is happening in the SDN movement [7].
We differ from KcKeown and some others in the conclusions drawn from this analogy;
specifically the apparent lack of recognition of the role that standards like IEEE Std 1003 (ISO/IEC 9945) [8] played in the proliferation of post mainframe era software.
We point out how this is related to what we observe in the carrier SDN space today.
We conclude by suggesting a model for, and steps by which, the OS movement and the whole SDN standards ecosystem can address
this major issue, one that, unaddressed will continue to challenge SDN adoption in some telco environments.
The presenter is co-chair of the ONF's Carrier Grade SDN discussion group, a contributor to the ONF's architecture document and active in SDN work in various other organizations including the ITU-T.
- http://yuba.stanford.edu/~jnaous/papers/ancs-openflow-08.pdf
- http://archive.openflow.org/wp/2011/03/open-networking-foundation-formed-to-speed-network-innovation/
- https://www.opennetworking.org/images/stories/downloads/sdn-resources/onf-specifications/openflow/openflow-switch-v1.5.0.noipr.pdf
- Operation, organization and business challenges for network operators in the context of SDN and NFV, Contreras et al (unpublished at this time)
- https://www.opennetworking.org/images/stories/downloads/sdn-resources/IEEE-papers/when-os-meets-nc-control-planes.pdf
- ITU-T JCA-SDN-D-001
- IET Appleton Lecture 2014, 30 April 2014, London
- http://pubs.opengroup.org/onlinepubs/009695399/
![]()
Biography:
Paul Doolan works in the CTO office at Coriant where he directs the company’s standardization activities. He contributes personally in ITU-T, BBF, ONF and IETF. Paul is a joint editor, with Fang Li of CATR, of the ITU-T SG15’s G.asdtn Architecture for SDN control of transport networks. In the SDN arena he is chair of the ONF’s Carrier Grade SDN project.

We have been developing an optical packet and circuit integrated network (OPCINet) as a high-speed
metro/core network infrastructure [1]. Previously, we have proposed and experimentally demonstrated architecture
for interworking between the OpenFlow-based networks and OPCINet by means of an OpenFlow-enabled
network-service testbed (RISE) and a ring-formed OPCINet [2][3]. Besides, we have proposed an
OpenFlow-based optical resource selection control to realize automatic data transfers from OpenFlow networks to
the OPCINet [4]. The OpenFlow controller (OFC) automatically selects one of the wavebands for OPS or a
wavelength for OCS in consideration of end-hosts’ quality of service (QoS) requirements and link-state information
(resource usage, congestion degrees in OPS links, etc) in the OPCINet. In [4], we have not fully discussed a
detailed policy for selection of optical resource (i.e. an OPS waveband or an OCS wavelength path).
In this work, we present a policy for optical resource selection to transfer diversified flows from OpenFlow
networks to the OPCINet. As illustrated in Fig.1, the OFC analyzes both end-hosts’ QoS requirements and OPS
links’ congestion degrees to determine which of OPS or OCS links should be selected. We employ values of ToS
(Type of Service) field (DSCP bits) embedded in packets and 8 classes specified in ITU-T Y.1541 [5] to define QoS
requirement. Table I shows the mapping among QoS requirements, the ToS values and Y.1541 classes. We
uniquely associate ToS values with Y.1541 classes. We define "High QoS" as ToS values of 232 and 200 (Classes
6,7), "Moderate QoS" as ToS values of 176, 144, 122, 80 and 48 (Classes 0,1,2,3,4), and "Low QoS" as ToS
values of 24 (Class 5). At all times, "High QoS" flows and "Low QoS" flows are transferred to OCS links and OPS
links, respectively. Here, in the Y.1541, Classes 0,1,2,3,4 (Moderate QoS) require the packet loss rate (PLR) of
less than 1 x 10-3, and classes 6,7 (High QoS) require the one of less than 1 x 10-5. Figure 2 shows the simulation
results of PLRs in a 100Gbps OPS link output form an 8-ports fiber delay line buffer. We assume that the arrival
rate (λ, packets per ns) follows a Poisson process and packet length distribution follows an exponential distribution
with average value of 141.6 bytes. The service rate of buffer (μ) is 100Gbps, and we set the unit delay length of
buffer at 16 ns. We can see that, when the load (ρ) is around 0.17, the PLR is 1 x 10-4. We assume the number of
hops in the OPCINet is 10, and therefore, the PLR in the OPCINet becomes around 10 times larger value, which is
1 x 10-3. Thus, if ρ in OPS links exceeds 0.17, "Moderate QoS" flows should be transferred to OCS links to satisfy
the QoS requirements; Otherwise, they should be transferred to OPS links. Then, if OCS links are selected, the
OFC computes and decides how to aggregate multiple flows into each OCS wavelength path by analyzing
statistical values of bytes transferred in OpenFlow switches (i.e. bit-rates) in OpenFlow networks. In this work, we
do not focus on aggregation algorithms, but multiple flows can be aggregated into an OCS wavelength path under
the condition that the sum of bit-rates of aggregated flows does not exceed the capacity of one wavelength (i.e.
10Gbps). We have partially implemented the resource selection control by means of an OFC, two OpenvSwitches,
and the ring-formed OPCINet, and confirmed that the control works correctly. The automatic resource selection
control will enable effective utilization of OPS/OCS resources with statisfying every end-host’s QoS requirement.
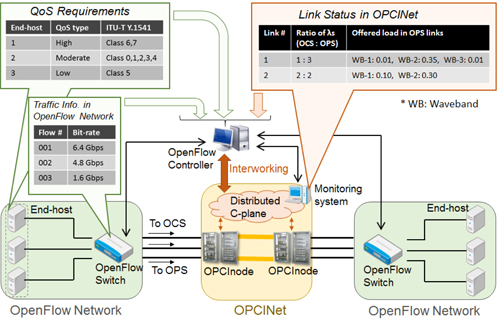
Fig.1 An image of automatic resource selection control
Tab.1 Mapping for QoS
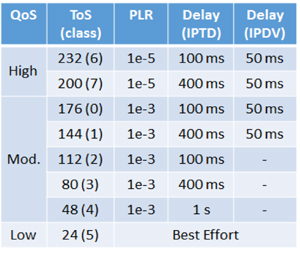
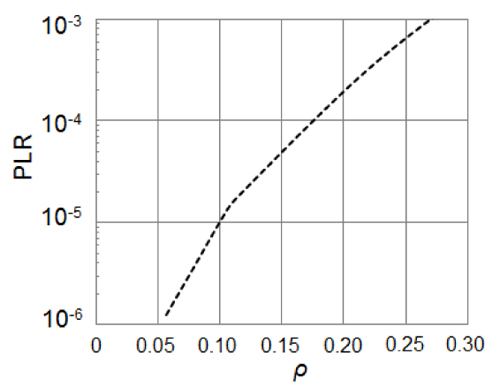
Fig.2 PLR in an OPS link
References:
- H. Harai, et al., IEEE/OSA Journal of Lightwave Technology, Vol.32, Iss.16, pp.2751-2759, Aug. 2014.
- T. Miyazawa, et al., IEEE Globecom Workshop on SDN on Optics, Atlanta, GA, USA, Dec. 2013.
- X. Cao, et al., ECOC 2014, Th. 2.2.4, Cannes, France, Sep. 2014.
- T. Miyazawa, et al., iPOP 2014, Tokyo, Japan, May. 2014.
- ITU-T Recommendation Y.1541 (12/11), https://www.itu.int/rec/T-REC-Y.1541-201112-I/en, Dec. 2011.
![]()
Biography:
Takaya Miyazawa received his B.E., M.E. and Ph.D. degrees in Information and Computer Science from Keio University, Yokohama, Japan, in 2002, 2004 and 2006, respectively. From 2006 to 2007, he was a visiting researcher at the University of California, Davis, USA. Since April 2007, he has been with the National Institute of Information and Communications Technology (NICT), Tokyo, Japan. He has been engaged in researches on optical network architecture. He is a recipient of the 2007 Hiroshi Ando Memorial Young Engineer Award and the 2010 Funai Young Researcher Award. He is a member of the IEEE, the OSA and the IEICE.

Due to the explosive traffic demand, 100 Gb/s Ethernet (100GE) standard was specified in 2010.
Along with the evolution of the link speed, the power consumption in network devices is also increasing. On the other hand,
current network are designed to handle with the peak-load and link failures. It brings the extra power consumption during
the low link utilization. Against the problem, many researches, which can reduce energy consumption when link utilization
is low, are studied. Adaptive Link Rate (ALR) can be taken as an example.
ALR is the technology, which can reduce power consumption by changing the link speed. When traffic demand is high,
high link rate are used and conversely, when traffic demand is low, low link utilization are used. Thus, ALR can get smaller
power consumption, however, as ALR reduces more power, the packet delay is also increases. In other word, power
consumption and packet delay are trade-off model in ALR. It is depend on the ALR policy. The more packet delay is caused
by two factors. The rate-switching time and the time which are sent in lower link rate.
To handle with the above problem, we propose the dynamic lane assignment scheme for each application in 100GE. This
proposal aims to solve two problems.
First, as described above, power consumption and packet delay are trade-off model. So, we propose a assignment scheme
for each traffic type. Traffic type is divided into two classes, delay-tolerant and not-delay-tolerant one. By assigning lanes to
each traffic type, each traffic type is handled by different ALR policy, so proposal scheme can realize both energy reduction
and less packet delay.
Second, the dynamic lane assignment scheme is proposed. The amount of the incoming packet is different every time, so
the dynamic lane assignment scheme for each application is needed.
Figure 1 shows the legacy 100GE architecture and Figure 2 shows the proposed 100GE architecture. To realize above
requirement, we propose the 100GE using coherent lightwave technologies. The proposal scheme can realize dynamic lane
assignment scheme for each application. We will evaluate the effectiveness of our proposal.
|
 |
| Fig.1 The legacy 100GE architecture | Fig.2 The proposed 100GE architecture |
![]()
Biography:
Takahiro Miyazaki was received the B. E degrees in computer science engineering from Keio University, Kanagawa Japan, in 2014.He is now a master course student of Keio University. His research interest includes optical network and green networking.

The first application of the transport SDN(Software Defined Networking) is mainly based on packet technologies and applied to interconnections between Data Centers.
In future, SDN employing both optical and packet technologies is promising for service aware transport network.
It requires higher bandwidth to support increasing traffic volumes, network flexibility and rapid provisioning of connectivity to transmit various type of services effectively.
This paper describes the multi-layer SDN with highly integrated packet-optical switch and policy-driven control technology.
The SDN for service aware transport network requires following technologies:
- Monitoring technology to recognize current network status in detail across multi-layer;
- Policy-driven network design and control technologies to calculate and set optimal route with considering defined policy and analyzed network status using the above monitoring data;
- Packet-optical integrated switching and mapping technologies to map and accommodate packet flow into a circuit path (e.g. Optical-channel Data Unit (ODU) of Optical Transport Network OTN)) or an optical wavelength path, flexibly, according to the above design result.
To confirm the above technologies, a proof of concept(PoC) as shown in Fig.1 has been constructed and
evaluated. It consists of routers, optical core nodes and centralized SDN Manager & Controller. The optical
core node has a highly integrated packet-optical switch (labeled "SDOP SW") in addition to an ODU cross
connect (ODU XC) and an optical wavelength switch (λ SW). The block diagram of the SDOP SW is depicted
at the left bottom of Fig.1. It can map certain packet flow into an ODU signal flexibly according to the flow
table that set that set by extended OpenFlow v1.3 protocolto control both ODU and wavelength paths. SDN
Manager & Controller has functionality of collecting & analyzing of monitored data, multi-layer path
calculation and provisioning of the calculated path. The design rule for multi-layer path calculation is
automatically updated to reflect both the defined policy and analyzed network situation.
The some scenario, such as "automatic path reroute from hop-by-hop path to optical cut-through path (see
Fig.1)" and so on, is demonstrated and then the possibility of service aware multi-layer transport network is
confirmed by using the PoC.
Fig.1 PoCconfiguration
Acknowledgement :
A part of this program is supported by "Virtualized network technology research and development(O3 project)" funded by Ministry of Internal affair and communication, Japan.
![]()
Biography:
Hiroaki Komine joined Fujitsu Laboratories Ltd. in 1985 and was engaged in research and development of ATM transport systems, self-healing network, network modeling and network management. He moved to FUJITSU Limited in 1993. After he worked for development of network management and control systems for ATM, SDH, IP and SDN, currently, he is working for SDN network management and control systems. He is a Fujitsu certified professional software product engineer. He received his B.E degree in electrical engineering from Tokyo University of Science in 1985. He is a member of IEEE.
"Management Issues in SDN/NFV era - What can we learn from cloud management and DevOps?-"
Coordinator: Kohei Shiomoto (NTT)
Panelists: Susan Hares (Huawei), Malathi Veeraghavan (Univ. of Virginia), Hiroaki Harai (NICT), Xiaoyuan Cao (KDDI R&D Labs.), Xi Wang (Fujitsu Laboratory of America), Satoshi Kamiya (NEC), Hidenori Inouchi (Hitachi)
Cloud and data center facilities are composed of mostly open standard technologies from device to system. We have been heavily used open standard management tools based on open standard IT technologies to operate and manage cloud and data center facilities. Management of cloud and data center facilities has been successfully almost "standardized" or "commoditized". Therefore management cost has been reduced.
On the other hand, carrier networks have been composed of diversified network elements including layer-3 routers, layer-2 switchers, L1/L0-transport nodes, SGSN/GGSN, S-GW/P-GW, eNodeB, NAT, FW, LB, IPS/IDS, DPI, CDN cache, etc. Network operators have been developing in-house management systems and tools to manage and operate their networks. Therefore management cost of carrier networks remains high.
Software-Defined Networking (SDN) / Network Functions Virtualization(NFV) are expected to play key roles for carriers to innovate network management. SDN/NFV introduces open standard IT technologies into carrier network management. We expect that management of carrier networks will be successfully almost "standardized" or "commoditized", and that management cost will be, therefore, reduced.
Based on this observation, in the closing panel, we will discuss management issues in SDN/NFV era. We will discuss what we can learn from cloud management and DevOps. Questions to be discussed in the closing panel may include (but not limited to):
- Management in SDN/NVF era
- Lessons from Cloud management and DevOps
- North-bound interface & South-bound interface
- Network modelling (Yang/Netconf)
- Virtual Network Operation (Performance/scaling/time issue)
- Multi-domain coordination issue
- Control-plane like interfaces (b/w multi-domain controller and domain controllers, b/w multi-domain controller and customer network controller)