Online Proceedings
*Notice: PDF files are protected by password, please input "ipop2013.9th". Thank you.
Thursday 30, May 2013
- Bijan Jabbari, iPOP General Co-Chair, Isocore, USA

Biography:
Shinji Shimojo received the M.E. and Ph.D. degrees from Osaka University in 1983 and 1986, respectively. He was an Assistant Professor with the Department of Information and Computer Sciences, Faculty of Engineering Science at Osaka University from 1986, and an Associate Professor with Computation Center from 1991 to 1998. During this period, he also worked for a year as a Visiting Researcher at the University of California, Irvine. He has been a Professor with the Cybermedia Center (then the Computation Center) at Osaka University since 1998, and from 2005 to 2008 had been the director of the Center. He is an executive researcher at National Institute of Information and Communications Technology and a director of Network Testbed Research and Development Promotion CenterNetwork Testbed Research and Development Promotion Center. His current research work is focusing on a wide variety of multimedia applications, peer-to-peer communication networks, ubiquitous network systems, and Grid technologies. He was awarded the Osaka Science Prize in 2005. He is a member of IEEE, and IEICE and IPSJ fellow.

Biography:
Adrian Farrel currently serves as one of two Routing Area Directors in the Internet Engineering Task Force (IETF). The mission of the IETF is to make the Internet work better by producing high quality, relevant technical documents that influence the way people design, use, and manage the Internet. The Area Directors are collectively responsible for technical management of IETF activities and the Internet standards process. Adrian's responsibilities include the stability and growth of the core routing system of the Internet: he is currently funded in this role by Juniper Networks.
Adrian co-founded network-planning and optimization start-up Aria Networks and runs a successful consultancy company, Old Dog Consulting, providing advice on implementation, deployment, and standardization of Internet Protocol-based solutions, especially in the arena of routing, MPLS, and GMPLS. He frequently speaks at conferences on topics ranging from Internet Governance to the future and meaning of Software Defined Networks (SDN). He is also the author or editor of five books on Internet protocols including The Internet and Its Protocols: A Comparative Approach (Morgan-Kaufmann, 2004), GMPLS: Architecture and Applications (Morgan-Kaufmann, 2005), and MPLS: Next Steps (Morgan Kaufmann, 2008).

In 2012, Infinera and ESnet have collaborated on the development of a SDN solution, Open Transport Switch (OTS), for transport networks. In November, the prototype had been deployed and tested in lived network for initiating, changing and terminating user connections using a modified version of OpenFlow, as illustrated below.
In this presentation, we will discuss the motivation behind OTS architecture, the design of the solution on both SDN controller and network equipment, the interface to existing GMPLS control-plane, and, finally, the enhancement to the OpenFlow 1.0 protocol.
During the deployment, we have experienced a number of issues in terms of network failure detection and propagation, and system resource discovery. These have laid the foundation for the new work in this area.
We conclude the presentation by describing the updated OTS architecture, including the configuration information model and OpenFlow 1.3 use cases. We are continuing the collaboration with a wide range of vendors and service providers in ONF.
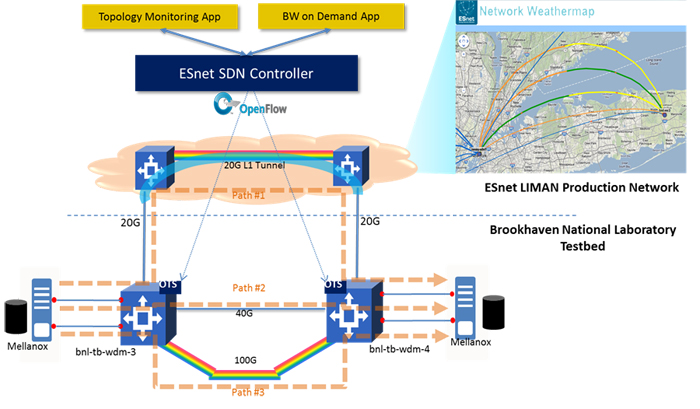 Fig.1
Fig.1
Biography:
Michael Frendo is the Vice President of Architecture at Infinera. He joined Infinera in 2010 and in his role is responsible for the hardware, software and optical architecture for Infinera's full suite of products. Prior to joining Infinera, Michael was General Manager, Unified Communications Solutions Business Unit at Avaya and responsible for the Integration of the Nortel Enterprise Solutions Business into Avaya.
Past roles included Senior Vice President and General Manager, High-End Security Systems (HSS) Business Unit at Juniper Networks. While there he was responsible for the leadership of the security and network traffic visibility technologies and products. Michael has also held positions at McDATA Corp where he was leading system architecture, worldwide product development and customer engagements for the Data Center products, Cisco Systems where he held the role of Vice President for Systems and Software Engineering within the Voice Technology Group and Bell Northern research where he was a leading development manager for the Magellan Passport product.
Frendo holds a PhD in Electrical Engineering from McMaster University in Hamilton, Canada.

We have proposed a packet transport node which has OpenFlow based control-plane and IP/MPLS-TP/Ethernet data-plane to realized flexible and on-demand control in multi-layer networks. We called the node P-PTN (Programmable Packet Transport Node). P-PTN is an OpenFlow switch controlled by OpenFlow controller through OpenFlow interface. Using P-PTN, we demonstrated that packet transport network (MPLS-TP) worked as a part of SDN (Software Defined Networking) based transport networks in iPOP2012 [1].
In this presentation, we demonstrate multi-layer network control scheme using P-PTN, where MPLS-TP OAM (Operation, Administration and Maintenance) can be set by OpenFlow controller. P-PTN has Y.1731 based MPLS-TP OAM functionalities. With the network control scheme, the controller can use APS (Automatic Protection Switching) in addition to OpenFlow’s route control. With APS, P-PTN improves reliability of SDN based transport network.
We had real-time video streaming tests from Okinawa to Tokyo through OpenFlow testbed RISE [2] on JGN-X [3] which is a wide area network testbed. Figure 1 shows experimental setup on RISE. We installed P-PTNs in two RISE sites in Tokyo. P-PTN OpenFlow controller configures MPLS-TP path and OAM for APS by OpenFlow messages (Flow_mod and Group_mod messages). The video streaming was the live video of baseball game, whose bit rate was around 30 Mbps. We confirmed that APS recovered from link failure less than 24 msec, and the video streaming quality was stably maintained without FEC (Forward Error Correction).
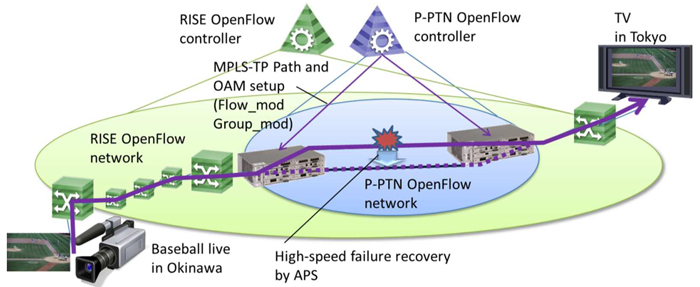 Fig.1 Experimental setup on RISE.
Fig.1 Experimental setup on RISE.
Acknowledgement:
We would like to thank RISE on JGN-X for experimental environment.
This work is a part of “Research & Development of Basic Technologies for High Performance Opto-electronic Hybrid Packet Router” supported by National Institute of Information and Communications Technology (NICT).
References:
- M. Hayashitani, et al., “Design and Implementation of OpenFlow-enabled MPLS-TP switch Prototype,” in Proc. iPOP 2012 3-4, Tokyo, Japan, May 2012.
- Y. Kanaumi, S. Saito, E. Kawai, S. Ishii, K. Kobayashi, and S. Shimojo, “Deployment and Operation of Wide-area Hybrid OpenFlow Networks,” in Proc. the Fourth IEEE/IFIP International Workshop on Management of the Future Internet (ManFI 2012), Maui, Hawaii, USA, Apr. 2012.
- New Generation Network Testbed JGN-X, http://www.jgn.nict.go.jp/english/index.html
Biography:
Masahiro Hayashitani received the B.E. and M.E. degrees in information and computer science from Keio University in 2005 and 2007, respectively. He is currently with Knowledge Discovery Research Laboratories, NEC Corporation. He is engaged in packet transport networks.

We have been developing an optical packet and circuit integrated (OPCI) network as a high-speed metro/core network infrastructure, in which both optical packet-switching (OPS) and optical circuit-switching (OCS) can be provided on the same fiber infrastructure [1] [2]. On the other hand, a centralized control protocol, OpenFlow, becomes widely used especially in data-centers, LANs, or network testbeds such as JGN-X [3]. Therefore, control systems in both OPCI networks and OpenFlow networks will be required to be interworked. In this work, we propose architecture for interworking between the OPCI network and OpenFlow-based networks.
We have developed OPCI nodes for a multi-ring topology [1]. OPS controls include header processing, switching, buffer scheduling, and so on. In each node, the OPS transfers each incoming optical packet from an input port to a output port by use of a label-ID. There is a “label mapping table” between label-IDs and values in a header field (currently, IP destination addresses of incoming 10GbE frames). At present, each label-ID corresponds to the unique ID of destination (i.e. dropping) node. On the other hand, autonomous distributed OCS controls (signaling, path routing, and dynamic resource allocations) [2] have been already connected to the OPCI nodes.
Figure 1 shows an example of interworking between the OPCI network controls and OpenFlow. We assume that OpenFlow-based networks are connected to the OPCI multi-ring network. In OpenFlow-based networks, we can define a “flow” by means of multiple header fields in packet at multiple layers. In addition, we build in the interface to interwork between OPCI network controls and OpenFlow. Concretely, the matching rule (i.e. values in related header fields) of each flow is mapped to corresponding OPCI network controls.
Interworking between OpenFlow and OCS controls: If an Ethernet frame with matching rule “A” comes from End-host-1 (EH-1) to OpenFlow Switch-1 (OFS-1), the OpenFlow controller (OFC) refers to the flow mapping database between matching rules and OPCI network controls, and requests the OCS controller in Node-1 to establish a unidirectional λ1 lightpath between Node-1 and Node-3 via Node-2. Then, the “flow table” in OFS-1 is updated to transfer the frame with matching rule “A” to the output port connected directly to the OCS transponder which changes 10GbE frames to OTU2e frames.
Interworking between OpenFlow and OPS controls: If an Ethernet frame with matching rule “B” comes from EH-1 to OFS-1, the OFC refers to the flow mapping database, and requests the OPS controller in Node-1 to update two tables: the label mapping table between label-IDs and matching rules and the “switching table” to control optical packet switches. The two tables are updated so that the optical packet is added in Node-1, gets through Node-2 and is dropped in Node-3. Then, the flow table in OFS-1 is updated to transfer the frame with matching rule “B” to the output port connected directly to the OPS transponder which changes 10GbE frames to 100Gbps multi-wavelength optical packets [1]. If an Ethernet frame with matching rule “C” comes from EH-1 to OFS-1, the OFC refers to the flow mapping database, and requests the OPS controller in Node-1 to update the label mapping table and switching table so that the optical packet is added in Node-1 and dropped in Node-2. Then, the flow table in OFS-1 is updated to transfer the frame to the output port connected directly to the OPS transponder.
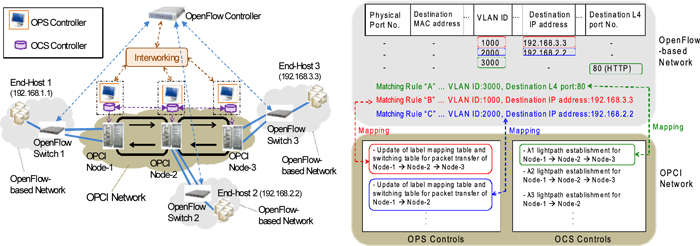 Fig.1 An example of interworking between the multi-ring OPCI network and OpenFlow-based networks.
Fig.1 An example of interworking between the multi-ring OPCI network and OpenFlow-based networks.
References:
- H. Furukawa, et al., Optics Express, vol. 20, Iss. 27, pp. 28764-28771, December 2012.
- T. Miyazawa, et al., J. Opt. Commun. Network, vol. 4, no. 1, pp. 25-37, January 2012.
- Y. Kanaumi, et al., in Proc. of the 4th IEEE/IFIP ManFI2012, pp.1135-1142, Hawaii, USA, April 2012.
Biography:
Takaya Miyazawa received his B.E., M.E. and Ph.D. degrees in Information and Computer Science from Keio University, Yokohama, Japan, in 2002, 2004 and 2006, respectively. From 2006 to 2007, he was a visiting researcher at the University of California, Davis, USA. Since April 2007, he has been with the National Institute of Information and Communications Technology (NICT), Tokyo, Japan. He has been engaged in researches on optical network architecture. He is a recipient of the 2007 Hiroshi Ando Memorial Young Engineer Award and the 2010 Funai Young Researcher Award. He is a member of the IEEE, the OSA and the IEICE.

Biography:
Alex Henthorn-Iwane joined QualiSystems in February, 2013 and is responsible for worldwide marketing and public relations. Prior to joining QualiSystems, Alex was Vice-President of Marketing at Packet Design, Inc., a provider of network management software, and has 20+ years of experience in senior management, marketing and technical roles at networking and security startups. Alex holds a Bachelor of Arts degree from U.C. Berkeley. Now, Alex is Vice President, Marketing, QualiSystems.

Biography: Shunji YOSHIYAMA received his B.E. degree in electrical engineering from Keio University in 1986. He joined NEC Corporation in 1986 and worked in the field of optical transport system development. And he is now a Chief Manager of the Converged Network Division and in charge of product planning of packet optical transport system.

This talk introduces our recent research on pursuing deep programmability within the network. Deep programmability refers to not only the control plane programmability, but also the data plane programmability for processing traffic data and parsing new protocols such as new L2 protocols and non-Internet protocols, as well as the programmability for defining APIs for control plane and data plane operations. The current Software Defined Network (SDN) research has not addressed the latter two kinds of programmability and only aims at the flexible and automated operation and management of networks, thus, the reduction of OPEX. We believe extending SDN to supporting deeper programmability further promotes the application of SDN.
We introduce a new network node architecture that enables deeply programmable network, called FLARE. The FLARE architecture introduces multiple isolated programming environments where we can flexibly and deeply program innovative in-network services such as new switching logics, packet caching, transcoding and DPI, and run them all concurrently at the line speed or switching among them on demand. We show demos and evaluations with the prototype of FLARE network nodes including running multiple switching logics such as OpenFlow 1.0 and OpenFlow 1.3 concurrently within a single FLARE node.
We also demonstrate a deeply programmable wireless access point called WiVi. The WiVi architecture slices access point resources and deliver multiple network services from multiple slices, such as a regular WiFi access point service as well as BeaconCast service, our newly developed protocol that can disseminate information to a large number of stations without authentication.
Biography:
Akihiro NAKAO received B.S.(1991) in Physics, M.E.(1994) in Information Engineering from the University of Tokyo. He was at IBM Yamato Laboratory/at Tokyo Research Laboratory at IBM Texas Austin from 1994 till 2005. He received M.S.(2001) and Ph.D.(2005) in Computer Science from Princeton University. He has been teaching as an Associate Professor in Applied Computer Science, at Interfaculty Initiative in Information Studies, Graduate School of Interdisciplinary Information Studies, the University of Tokyo since 2005. (He has also been an expert visiting scholar/a project leader at National Institute of Information and Communications Technology (NICT) since 2007.

Communication Service Provider (CSP) networks use a variety of proprietary appliances for network function when delivering services. Therefore, deploying a new network function often requires new hardware components. Integrating new equipment into the network requires space, power and the technical knowledge to deploy and operate the new network function. This problem is compounded by function and technology lifecycles which are becoming shorter as innovation accelerates in an increasingly network-centric connected world.
The concept of virtualization is well-known and has been used for many years, including operating system virtualization (Virtual Machines) [1]; computational and application resource virtualization (Cloud Computing) [2]; link and node virtualization (Virtual Network Topologies) [3]; and data center virtualization (Virtual Data Center) [4].
Network Functions Virtualization (NFV) is a new industry initiative [5] and aims to leverage existing virtualization concepts to consolidate function-specific network equipment onto standard high volume servers [6], switches and storage, which could be located in network nodes, data centers or at enterprise customer sites.
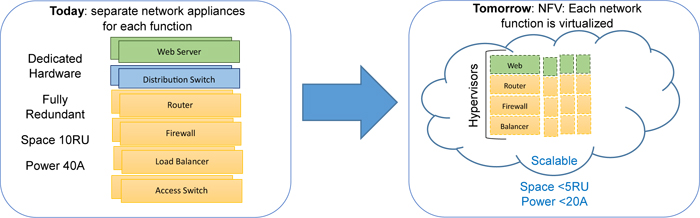 Fig.1
Fig.1
This proposal utilises grounded theory within a critical survey to investigate the economic and technical requirements for NFV, from the network operator perspective. Using semi-structured interviews with network operators, the survey documents NFV motivation, requirements, ranking issues, recurrent themes and common use cases. These results will be presented with findings and conclusions during the presentation.
References:
- Barham, Paul, et al. "Xen and the art of virtualization." ACM SIGOPS Operating Systems Review. Vol. 37. No. 5. ACM, 2003.
- Fox, Armando, and R. Griffith. "Above the clouds: A Berkeley view of cloud computing." Dept. Electrical Eng. and Comput. Sciences, University of California, Berkeley, Tech. Rep. UCB/EECS 28 (2009).
- E. Oki et al., “Framework for PCE-Based Inter-Layer MPLS and GMPLS Traffic Engineering”, RFC 5623, September 2009.
- Guo, Chuanxiong, et al. "Secondnet: a data center network virtualization architecture with bandwidth guarantees." Proceedings of the 6th International Conference. ACM, 2010.
- Authored by ETSI members (Network Operators). “Network Functions Virtualization whitepaper, an introduction, benefits, enablers, Challenges & Call for Action”, October 2012, NFV ISG, ETSI.
- Network Function Virtualization Or NFV Explained - Wikibon. 2013. [ONLINE] Available at: http://wikibon.org/wiki/v/Network_Function_Virtualization_or_NFV_Explained.
Biography:
Daniel is a PhD student with the Computing Science Department at Lancaster University, where he is researching Network Functions Virtualisation (NFV). He is also a part-time consultant at Old Dog Consulting. Prior to Old Dog Consulting he worked for Movaz Networks, Redback Networks, Cisco Systems, and Bell Labs.
Daniel has presented, chaired and a technical programme committee member at numerous telecoms related conferences. He is also an active contributor within the IETF. Specifically within the PCE, MPLS, L3VPN and CCAMP working groups and is an editor and author on numerous IETF Internet-Drafts and RFCs related to path computation, MPLS, GMPLS and network optimization. Daniel is the Secretary of four IETF working groups, namely PCE, CCAMP, ROLL and L3VPN.

As carrier networks are evolving to multi-domain, multilayer and multivendor architecture, simplification, automation and scalability are key factors that must be provided. Software Define Networking (SDN) presents an opportunity to meet these challenges for transport networks. Our proposed SDN architecture provides a programmable and scalable solution for transport networks. This is achieved by (1) A SDN controller architecture that decouples virtual control from physical control; (2) A SDN orchestration architecture that allows a seamless coordination/orchestration between application and network and joint resource optimization.
The real benefit of SDN for transport networks may come from network virtualization capabilities via the programmable interfaces (termed as Client Virtual Network Interface (CVNI)) with client/application and the virtual control and management capability in the controller. New applications and services that this interface supports include both external customer applications (e.g., cloud bursting, virtual network slicing, bandwidth on demand, etc.) and internal applications (e.g., service specific routing, etc.). SDN CVNI provides open and programmable interfaces allowing a plethora of new applications/services plug-ins to be dynamically created via the interaction with the controller’s virtual control and management module.
The Virtual Network Control and Management (VNCM) module is a part of the SDN controller and interacts with applications via the CVNI in a fairly technology-agnostic and virtual fashion. Among the key functions of the VNCM is topology abstraction, both generic and service-specific. These abstraction capabilities are useful to expose to applications that need to understand underlying network resource information from the application’s standpoint. Generic topology abstraction allows the hiding of details of the real physical network topology and provides generic information such as network end points with or without some bottleneck links and path level cost, etc. A service-specific topology provides a deeper level of abstraction from generic topology to service specific. It is abstracted and reduced view of a limited set of network sources and destinations with some prime service-specific objectives such as (a) lowest monetary cost, (b) lowest latency, (c) highest reliability, (d) high bandwidth.
Our SDN architecture is based on standard interfaces and the utilization of control plane to delegate some functionality, which allows multi-vendor support. Simulation results demonstrate a substantial economic benefit with this architecture for transport networks.
Biography:
Young is currently Principal Technologist at Huawei Technologies USA Research Center, Plano, Texas. He is leading optical transport control plane technology research and development. His research interest includes SDN, cloud computing architecture, cross stratum optimization, network virtualization, distributed path computation architecture, multi-layer traffic engineering methodology, and network optimization modeling and new concept development in optical control plane signaling and routing.
Prior to joining to Huawei Technologies, Young was a co-founder and a Principal Architect at Ceterus Networks (2001-2005) where he developed topology discovery protocol and control plane architecture for optical transport core product. Prior to joining to Ceterus Networks, Young was Principal Technical Staff Member at AT&T/Bell Labs in Middletown/Holmdel, New Jersey. At AT&T Labs (1996-2000), he was responsible for core IP/MPLS network architecture evolution and AT&T End-to-end architecture planning. He also involved voice/data convergence architecture planning and evolution. At Bell Labs (1987-1995), Young was responsible for developing dynamic routing schemes and traffic network management control and measurement development. He is currently active in IETF PCE and CCAMP WGs and ONF OTWG and is a co-author of several RFCs. He holds several patents in the area of dynamic routing and switching technology and several patents pending in optical networking.
Young Lee received B.A. degree in Applied Mathematics from the University of California at Berkeley in 1986, M.S. degree in Operations Research from Stanford University, Stanford, CA, in 1987, and Ph.D. degree in Decision Sciences and Engineering Systems from Rensselaer Polytechnic Institute, Troy, NY, in 1996. He is a member of IEEE and Alpha Phi Mu honor society.

Lately, cloud services have been becoming popular, and systems for providing these services are rapidly being expanded. As a result of these trends, the amount of electric power consumed by these systems has been dramatically rising, and devising power-saving schemes for them is becoming a major challenge. Aiming to address this issue, we have been developing a “power-saving cloud system.” In this study, as a software-defined networking application, a scheme for power-saving control of the cloud system is proposed.
A typical structure of the proposed power-saving cloud system is shown schematically in Fig. 1. The system is composed of multiple data centers (DCs), and a wide-area network (WAN) connecting them, in addition to a WAN-management server, an integrated DC-management server, a DC-management server, and a user-management server. The integrated DC-management server initiates optimal reallocation of VMs belonging to each user when the loads on VMs are low (such as in the late evening). The WAN-management server monitors and predicts future loads on the network (WAN). In addition, it determines whether network congestion occurs or not after each VM reallocation. Besides, the WAN-management server controls the power consumed by switches according to traffic. The DC-management server monitors conditions of shared network resources (such as switches) and predicts a load on the network in the DC. The user-management servers, which might be implemented on physical servers, explore several options for power-saving VM allocation according to future loads by cooperating with the other user-management servers. In addition, it verifies whether network congestion occurs in the WAN after each VM reallocation among DCs by sending an enquiry to the WAN-management server through the integrated DC-management server. Moreover, the user-management server makes a final VM-reallocation layout to achieve the most effective power-saving without causing WAN congestion. Since each VM-reallocation process is executed separately from other processes, the proposed power-saving management scheme is suitable for large-scale cloud systems.
To evaluate the proposed scheme, a prototype system composed of four DCs and a network connecting them was implemented. In this system, a total of 100 VMs are executed on 100 servers. These resources are divided and located in each DC and shared by two users equally. The evaluation results verify that the scheme calculates an appropriate VM reallocation layout for a power-saving cloud for each user resource in parallel.
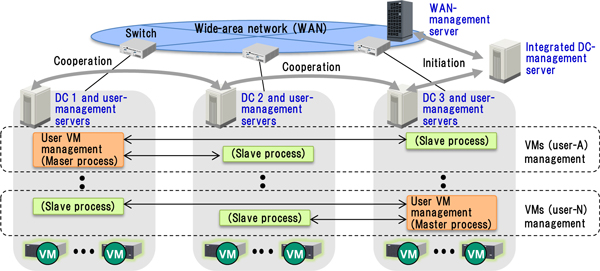 Fig.1 Proposed power-saving cloud system.
Fig.1 Proposed power-saving cloud system.
Acknowledgement:
Part of this research was supported by the MIC (Japanese Ministry of Internal Affairs and Communications) projects “Research and Development on Signaling Technology of Network Configuration for Sustainable Environment” and “Research and Development on Power-saving Communication Technology - Realization of the Eco-Internet”.
Biography:
Toshiaki Suzuki received his BS and MS in physics from Tokyo University of Science, Japan, in 1990 and 1992, respectively. He joined Hitachi, Ltd., Central Research Laboratory in 1992. He visited Hitachi Europe Ltd. to study active networks from 2000 to 2003. Currently he is a senior researcher of the Network Systems Research Department. He is actively engaged in the research of cloud systems.
Friday 31, May 2013

Biography:
Atsushi Iwata joined NEC Corporation in 1990 and has been working for research and development of ATM, IP/MPLS, Metro Ethernet, CDN, and SDN/OpenFlow, NFV and server virtualization since then.
From 1997 to 1998, he was a visiting researcher at UCLA where he was working for research activities of Multi-hop Adhoc Wireless Network (MANET).
From 2009 to 2011, he moved to IP network division to develop SDN/OpenFlow-based Datacenter switch products as ProgrammableFlow datacenter solutions.
In 2011, he moved back to Central Research Labs, and since then he has been leading SDN/NFV research activities in Knowledge Discovery Research Laboratories, as a Deputy General Manager.
He received the B.E., and M.E., and Ph.D. degrees in electrical engineering from the University of Tokyo, Japan, in 1988, 1990, and 2001 respectively.

Biography:
Jonathan Sadler is a Senior Product Planner in the Optical Network Group at Tellabs.
With over 25 years of data communications experience as a protocol implementer, network element designer, carrier network operations manager, and carrier network planner, Jonathan brings a broad set of knowledge and experiences to the design and analysis of carrier network technology.
Currently, Jonathan is involved in the development of technologies providing the efficient transport of packet oriented services in carrier networks. Jonathan is the Chairman of the Optical Internetworking Forum's Technical Committee and an active participant in both ITU and IETF. Jonathan studied Computer Science at the University of Wisconsin - Madison.

I. Introduction In terms of maximum utilization of network resources, we need to efficiently exploit both legacy (e.g. SONET/SDH, and 10Gb/s DWDM systems) and new (e.g. OTN, and 100Gb/s digital coherent-based DWDM systems) transport equipment from carrier’s perspective. However, since the optical transport networks including both legacy and new equipment are becoming more complex, actually it would be difficult to manually design end-to-end paths in multi-technology optical transport networks. In this paper, we demonstrate a Shortest Path algorithm using Graph Transformation (SPGT) technique [1,2], which is possible to alleviate multiple constraints in the path computation for multi-technology optical transport networks. Fig.1 shows network graphs of a multi-technology optical transport network before and after graph transformation. In addition, we show that our method can perform a path computation with a smaller computation time in a relatively large-scale network consisting of SDH/OTN/WDM equipment with several interface types (e.g. GbE and STM-16) compared to the conventional multi-constrained shortest path (MCSP) [3].
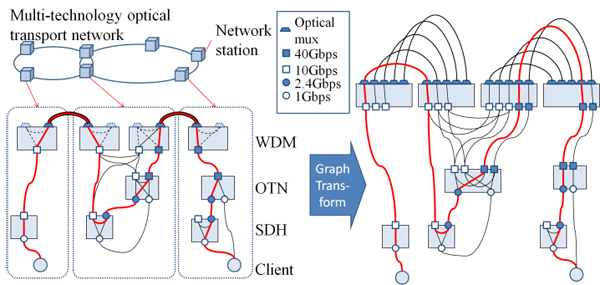 Fig.1 Illustration of a multi-technology optical transport network before and after graph transformation.
Fig.1 Illustration of a multi-technology optical transport network before and after graph transformation.
II. Results and discussions Fig.2 shows four network ring topologies with different network sizes for evaluations and the calculated result of the computation time as a function of network sizes in both cases of SPGT and MCSP. A network ring consists of 4 network stations. When connecting two rings, two neighbor WDM nodes are connected as shown in Fig.2. In each network station, we assume that three different transport node types such as a WDM in each ring, an OTN and an SDH equipment are existing. The WDM and OTN nodes have four client and line interface types such as GbE, STM-16, STM-64, and OTU3, respectively. In addition, the SDH node has three client and line interface types such as GbE, STM-16, and STM-64. We evaluated a computation time to search a route of an end-to-end GbE path between source node (S) and destination node (D) using the SPGT and the MCSP based on Dijkstra[4] for comparison. It’s noted that each plotted computation time represents the average value of 100 measurements. In the case of more than two network rings, we found that the computation time of the SPGT was smaller than that of the MCSP. Especially, the computation time of the SPGT was less than 1/5000 compared with that of the MCSP in the case of 9 network stations (4 rings) consisting of 34 nodes with total 143 interfaces. It was confirmed that the SPGT could reduce the computation time in the large-scale networks.
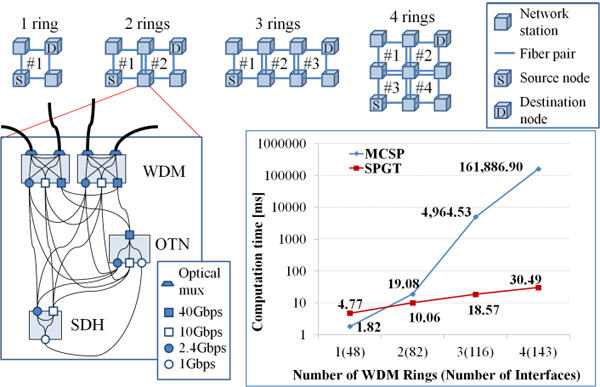 Fig.2 Simulated network configuration and the calculated results. (OS: Windows 7 SP1, CPU: Intel 3.4GHz, RAM: 8.0G)
Fig.2 Simulated network configuration and the calculated results. (OS: Windows 7 SP1, CPU: Intel 3.4GHz, RAM: 8.0G)
References:
- B. Jabbari et al., IEICE Trans. Commun. Vol.90-B, No. 8, pp. 1922-1927, Aug. (2007).
- X. Yang et al., IEEE ICC 2009, Dresden, Paper 5198679, Jun. (2009).
- T. Korkmaz et al., IEEE INFOCOM 2001, Anchorage, Alaska, Vol.2, pp. 834-843, Apr. (2001).
- E. W. Dijkstra, Numerische Mathematik, 1, No. 1, pp.269-271 (1959).
Biography:
In 2011, I received Master of Engineering degree from Yokohama National University, and joined KDDI R&D Laboratories Inc..
Now I am engaged in the development of system for designing optical transport network.

Many kinds of network services are provided through access networks. Examples of services are following: an FTTH service for residential users, a mobile backhaul service used by mobile operators, a leased line service for business customers, and a micro datacenter connection service for datacenter operators. An aggregation network exists between access networks and a core network physically. We are now challenging to move the aggregation function to both the access and core networks. This leads to fully optical data transport from the access to the core network. To realize service integration into FTTH, MPLS-TP technologies are very attractive. MPLS-TP offers services over MPLS-TP over Ethernet (i.e., over FTTH). IP, Ethernet, MPLS, MPLS-TP, ATM, and SDH can be integrated into a single access and aggregation integrated optical network. We have proposed an Elastic Lambda Aggregation Network (EλAN) [1]. EλAN has strong characteristics in the extension of FTTH, the elastic optical network named Optical Distribution Network (ODN), and the high-flexibility realized by aggregate functions of a wide area virtual layer-2 (VL2) network and programmable OLTs/ONUs. EλAN should have MPLS-TP adaptation function and control both Ethernet paths that are set between VL2 network and ONUs and optical paths that are set between OLTs and ONUs via ODN. Focusing on the high-flexibility, a multi-layer path control method is required. We try to apply an OpenFlow protocol to realize the multi-layer path control in EλAN. The details and advantages of our new control method are following.
- Control method of VL2 network: We choose SDN/OpenFlow to control switches on the VL2 network. Data frames of each service are encapsulated into Ethernet frames (via MPLS-TP) so that all services can be monitored and an OpenFlow Controller (OFC) can manage their routes.
- Control method of ODN: In order to provide services and optical paths for users dynamically, we extend OFC to control ODN devices (i.e., optical switches). Specifically we try to extend three functions; protocol extension for collecting information of ODN devices, optical path routing based on the collected information at OFC, and protocol extension for controlling ODN devices.
At the presentation, the feasibility of the proposed control method will be reported. Demonstration will be also held at the exhibition area.
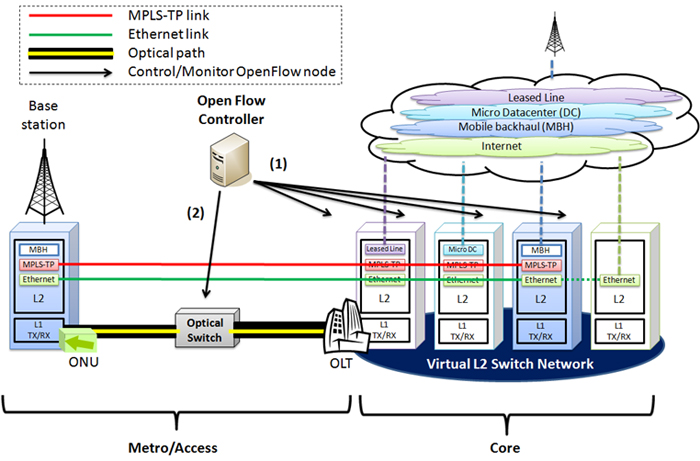 Fig.1
Fig.1
References:
- S. Okamoto, “Elastic optical metro/access combined aggregation network technologies for realizing a future service adaptive network paradigm,” Proc. in IEICE Technical Report on Communications Systems, CS2012-96, Jan. 2013.
Biography:
Yuki Higuchi received his B.E. degree from Keio University, Japan, in 2012. Currently, he is second-year master’s degree student at Keio University. He engages in research on service adaptation method of the next generation optical network. He is a student member of the Institute of Electronics, Information and Communication Engineers (IEICE) of Japan.

Elastic Optical Networks (EON) [1] provide scalable, flexible and spectrum-efficient optical transport, which may be used for a variety of high growth applications. These applications include large scale content distribution and data center inter-connectivity. EONs place a set of new requirements on the operation of the network, where existing network operation methods are simply not sufficiently capable. These include, on-demand and application-specific reservation of flexible optical network connectivity, reliability, resources (such as bandwidth) and policy.
Software Defined Networking (SDN) and network programmability offer the ability to direct application service requests towards the optical network. By combining the Path Computation Element (PCE), an application service request can utilize a well-defined set of path computation and traffic engineering (TE) features. This functionality can be categorized as Application-based Network Operations (ABNO) [1].
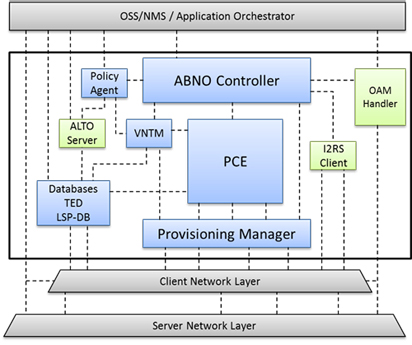 Fig.1
Fig.1
This presentation describes how SDN and PCE can be applied to enhance an EON [3]. It demonstrates how these technologies may be combined to solve a critical EON use case, Global Concurrent Optimization (GCO) [4] of network resources. We will detail how the ABNO key components and procedures may be used, including: policy control, resource (spectrum frequency) gathering, path computation and optimization of objective functions, traffic engineering and scheduling. Finally we will summarize the quantitative benefits of the ABNO-enabled GCO operation, in terms of capabilities, network utilization and operational efficiency.
Technologies:
EON, ABNO, GCO, GMPLS, SDN, Network Programmability, Dynamic, Management, Automation, Policy.
Acknowledgement:
This work was partially funded by the European Community’s Seventh Framework Programme FP7/2007-2013 through the Integrated Project (IP) IDEALIST under grant agreement n° 317999.
References:
- Elastic Optical Networks: the Vision of the ICT Project IDEALIST.
- A PCE-based Architecture for Application-based Network Operations.
- IDEALIST Control and Service Management Solutions for Dynamic and Adaptive Flexi-grid DWDM Networks.
- Path Computation Element Communication Protocol (PCEP) Requirements and Protocol Extensions in Support of Global Concurrent Optimization.
Biography:
Daniel is a part-time consultant at Old Dog Consulting. Prior to Old Dog Consulting he worked for Movaz Networks, Redback Networks, Cisco Systems, and Bell Labs. He is also a PhD student with the Computing Science Department at Lancaster University, where he is researching Network Functions Virtualisation (NFV).
Daniel has presented, chaired and a technical programme committee member at numerous telecoms related conferences. He is also an active contributor within the IETF. Specifically within the PCE, MPLS, L3VPN and CCAMP working groups and is an editor and author on numerous IETF Internet-Drafts and RFCs related to path computation, MPLS, GMPLS and network optimization. Daniel is the Secretary of four IETF working groups, namely PCE, CCAMP, ROLL and L3VPN.

Path Computation Element (PCE) in MPLS-TE network can provide a headend LER with LSP attributes that includes route information, bandwidth and essential parameters for RSVP-TE signaling. Using PCE Communication Protocol (PCEP) defined in RFC5440, PCE computes End-to-End path only when it receives PCC’s path request. It does hold neither network conditions nor LSP operational status. In other words, PCE controls PCCs in “stateless” manner.
Recently, Stateful PCE and its corresponding protocol extensions were proposed in IETF and recognized as one of Software Defined Network (SDN) southbound interfaces. It provides a mechanism that enables PCE to do “stateful” control of synchronized and delegated LSP. The PCC allows the PCE to manipulate LSP operational state, route and bandwidth immediately. Moreover, the PCC enables to create new LSP by the PCE's instruction.
Considering a proactive preparation for a planned maintenance, the network operators must reroute all in-service LSPs to traverse the specific maintenance node in advance.
Using stateless PCE, there is only one practical way for the network operators to do LSPs' restoration and reoptimization: network operators instruct all headend PCCs to request path computation to PCE with a certain constraint for rerouting. On the other hand, using stateful PCE, the network operators can put the intended route information into the PCE. The PCC receives both rerouting instruction and the result of rerouting path from the PCE. This can be much simpler and centralized operation, which is suitable for large-scale network.
This presentation introduces mechanism for a LSP restoration and reoptimization using stateful PCE. We propose two types of control procedures:
One Stroke mode - The whole procedure of rerouting in Make-Before-Break (M-B-B) method is handled by the headend PCC. It has high affinity with most existing MPLS edge node implementations which perform entire steps of M-B-B automatically at once.
Granular mode - the PCE can control decomposed M-B-B steps with proper timing and sequence. It is much more flexible than One-stroke mode since it allows PCEs to manage each LSP step-by-step and it is widely applicable to several new use cases that require split control of signaling and data switchover.
This presentation also shows the applicability of out proposed method to service provider's network under emerging SDN environment.
Biography:
Yosuke Tanaka joined NTT Communications Corporation, Tokyo, Japan in 2008. Since joining Innovative Architecture Center, NTT Communications Corp., Tokyo, Japan, Yosuke has been involved in development of IP/Transport networks related to MPLS/VPN/P2MP multicast network, and currently focuses on Software Defined Network(SDN). Yosuke received his B.Sc and M.Sc degree in Information Technology from the University of Tokyo, Japan in 2006 and 2008.

Many centralized architectures incorporate stateful PCE as one of the building blocks of the solution they provide. A classic example is that of a traffic optimization system. Such a system can help keep costs down while providing tight SLAs by optimally placing LSPs and continuously re-optimizing them based on feedback from the network, using PCE as its central computation engine.
This talk will examine several use cases and evaluate the role a stateful PCE plays, the benefits it brings, and how it can interact with other components in the network. In this process, we will also look at gaps in existing functionality, some of the work in progress today and possible future extensions for stateful PCE.
Biography:
Ina Minei is a Distinguished Engineer at Juniper Networks, where she works on next-generation network technologies for the CTO office. Her current interests include stateful PCE and MPLS. She is co-author of several of the stateful PCE drafts in the IETF, as well as of the book "MPLS-enabled applications" now in its third edition.

Due to the explosion of IP traffic, one of main issues for network operators is how to reduce CAPEX and OPEX for a core network with large capacity. IP routing layer is usually overlaid over transport path layer in a core network. Network operators usually manage IP routes by means of distributed routing protocol and transport paths by means of static configuration from centralized network management system.
We introduce a centralized approach for integration of IP routing and transport path management. In our approach, a transport network controller is deployed in a core network and it performs both of IP routing and transport path management. The controller is logically centralized and responsible for configuring both of IP and transport path forwarding tables in all the edge and core nodes. The decoupling of IP routing and forwarding allows deployment of low-cost edge nodes without any IP routing protocol processing. Also it is expected to facilitate network maintenance such as field upgrade because it doesn't rely on distributed protocol.
We have implemented a prototype of transport network controller to perform IPv4 unicast and multicast routing to show the feasibility of a centralized approach for IP routing. The controller supports edge nodes with Ethernet interface. The controller utilizes OpenFlow protocol for configuring the IP forwarding tables in edge nodes and also for performing "packet-in/out" of control packets such as ARP and ping.
We present how the controller computes and configures flow entries in the forwarding tables in edge nodes. A routing prefix and its next hop address outside a core network is provided to the controller statically or dynamically. It makes a single routing table of the entire core network as if all the edge routers are grouped into a single virtual router. The controller computes flow entries in the forwarding tables in edge nodes based on the routing table of the entire core network. Specifically, a next hop address is modified correctly by utilizing topology information of transport paths such as MPLS-TP paths in a core network. Here, we assume that transport paths are pre-configured when the controller computes flow entries.
We also show how network failure can be recovered by the modification of flow entries by the controller. As an example, we will present a network failure recovery mechanism in two cases: (1) network failure inside a core network, (2) network failure between an edge and external node that is outside a core network.
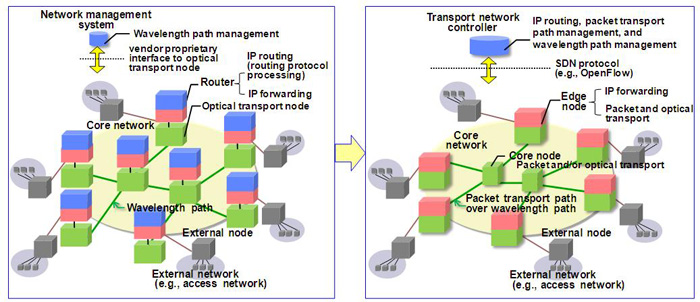 Fig.1 Simplification of core network
Fig.1 Simplification of core network
Biography:
Takafumi Hamano received the Master's degree in Engineering from Kyoto University, Japan in 1996. He is currently with the NTT Network Service Systems Laboratories and working on R&D of next generation carrier backbone networks.

We have designed and implemented OpenFlow-enabled MPLS-TP (Multi-Protocol Label Switching-Transport Profile) switch prototype to realize flexible automation control in transport network by SDN (Software Defined Networking) [1]. In OpenFlow-enabled MPLS-TP network, both MPLS-TP (D-plane) and OpenFlow (C-plane) have failure-recovery scheme. MPLS-TP has APS (Automatic Protection Switching) function that enables high-speed protection because APS operates in only D-plane [2]. However, MPLS-TP does not support both failures in APS group (a pair of working and protection paths). On the other hand, OpenFlow can support multiple failures by centralized control. But OpenFlow based failure-recovery is not fast because the failure-recovery operation includes the OpenFlow controller action. Therefore, it is necessary to decide which failure-recovery scheme (D-plane or C-plane) to choose according to failure types in order to realize high reliable transport networks.
In this presentation, we propose a selection method of failure-recovery scheme by OpenFlow controller in OpenFlow-enabled MPLS-TP networks. In the method, the OpenFlow controller selects failure-recovery scheme based on path information in the controller and OpenFlow messages from OpenFlow-enabled MPLS-TP switches. Figure 1 shows an overview of the failure-recovery selection method. In the proposed method, the OpenFlow controller receives Port Status messages from the OpenFlow switches, and recognizes failure point(s) based on Port Status messages. The controller compares each path including APS group information with failure point(s), and knows each impaired path. Next, the controller selects the failure-recovery scheme according to each impaired path. If the impaired path is included in APS group, the controller selects D-plane based recovery in case of single impaired path in APS group, and selects C-plane based recovery in case of both impaired paths in APS group. If the impaired path is not included in APS group, the controller selects C-plane based recovery.
We demonstrated the selection method by using OpenFlow controller Trema [3] and MPLS-TP switches. We show the proposed method can select appropriate failure-recovery scheme based on the OpenFlow message from the switches.
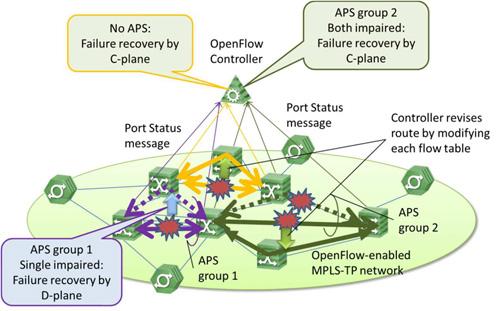 Fig.1 Overview of failure-recovery selection method.
Fig.1 Overview of failure-recovery selection method.
Acknowledgement:
This work is a part of “Research & Development of Basic Technologies for High Performance Opto-electronic Hybrid Packet Router” supported by National Institute of Information and Communications Technology (NICT).
References:
- M. Hayashitani, et al., “Design and Implementation of OpenFlow-enabled MPLS-TP switch Prototype,” in Proc. iPOP 2012 3-4, Tokyo, Japan, May 2012.
- W. Xie, et al., “An improved ring protection method in MPLS-TP networks,” in Proc. IC-NIDC 2010 24-26, Beijing, China, Sept. 2010.
- Trema, Full-Stack OpenFlow Framework in Ruby and C, http://trema.github.com/trema/
Biography:
Masahiro Hayashitani received the B.E. and M.E. degrees in information and computer science from Keio University in 2005 and 2007, respectively. He is currently with Knowledge Discovery Research Laboratories, NEC Corporation. He is engaged in packet transport networks.

Originally the OpenFlow switch model [1] targeted a complete separation of control plane and data plane, where all stateful processing resided on the controller. The switch was only capable of executing stateless processing: incoming packets were processed based on flow rules, but not on previous flow events or other external events. The protocol evolved with preserving this stateless nature, focusing on multiple tables, new match and action semantics.
Yet from time to time there was a need for including stateful processing to the OpenFlow switch. IP defragmentation support, output queues, meters and logical port tunnels (via OF-Config) were gradually added to the switch specification [2]. Stateful processing was never accepted as a first class citizen in the OpenFlow pipeline. As a result, these features were added in an ad-hoc manner on a case-by-case basis. As a result, the availability of these features are inconsistent: defragmentation is only available before the pipeline (on the switch level), logical ports are only available before and after the pipeline, while meters can be accessed inside the pipeline.
We propose the addition of a new first class entity to the OpenFlow pipeline model, called packet processor (PP) [3]. These PPs are capable of emitting and consuming packets and can also be chained between the flow tables (Figure 1.).
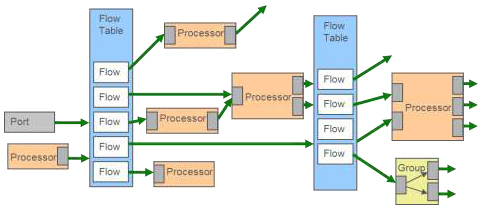 Fig.1 Packet Processors in the OpenFlow pipeline
Fig.1 Packet Processors in the OpenFlow pipeline
The packet processor proposal defines the above architecture, and the associated message framework. It enables the introduction of any sort of stateful processing capability in the middle of the pipeline. The different types of PPs would be stored in a registry. The controller is capable of instantiating processors based on their ids - and chaining them to the pipeline similar to how flow tables are chained today. The message framework makes it possible for the controller to send and receive opaque data to and from packet processors; the message contents being defined along with the PP type.
It is important to note that while the packet processors are logically instantiated in the middle of the pipeline, it is not mandated that hardware targets implement it so. On platforms, where the pipeline is not capable of stateful processing, the local OF agent can instantiate PPs on external devices (e.g., the control processor), and steer traffic from the pipeline to the PP process and back - transparent to the controller.
The packet processor proposal is backward compatible with existing OpenFlow pipelines, as existing features can be used as before. However, PPs are also able to model existing stateful (e.g., output queues, meters) and stateless (e.g., apply instructions, groups) processing of the current pipeline. Thus, PPs could become the basis of reorganizing the OF pipeline in a way, that every packet processing is modeled as a PP, and flow tables are reduced to steering packets between PPs via matching.
We demonstrate the capabilities of packet processors by implementing the framework and a few examples on an open source OpenFlow software switch.
Our first example is a packet processor that supports local discovery by emitting and consuming LLDP [4] packets. Once instantiated, the controller can program this PP to emit specific LLDP packets, which are then steered to different output ports via flow entries. Similarly incoming LLDP packets are steered to the local discovery PP, which consumes them. This way the PP is capable of maintaining a local neighbor database, and can notify the controller on changes.
We contrast this PP to the current practice of topology discovery - where LLDP packets are handled by controller packet-ins and packet-outs - and show that using the PP significantly reduces the control traffic.
In our second example we implement a GRE [5] ingress and egress packet processor pair. These stateless PPs can be instantiated and chained to arbitrary locations at the pipeline. They will encapsulate and decapsulate any GRE traffic that is steered towards them.
GRE functionality is already supported by the latest OpenFlow switch specifications using logical ports, the packet processor based solution provides versatility. First, the logical port based solution requires that the tunnel traffic arrives directly to the port. If the tunnel traffic is encapsulated in further tags or tunnels, it cannot be handled by logical ports. Second, the logical port based solution requires a hybrid OpenFlow switch (i.e., one with a local network stack), as the current specification does not enable further pipeline processing of the encapsulated packets; e.g., to do ARP and forwarding of packets.
Finally we demonstrate a BFD [6] based packet processor. This PP emits BFD packets on its output port, and receives BFD packets from the associated reverse direction on its input port - internally executing the standard BFD state machine. The BFD packets are steered to and from the PP using standard flow based processing.
We show that our framework is interoperable with traditional networking equipment by setting up an MPLS LSP - protected by BFD - between an OpenFlow network and an IP/MPLS router.
References:
- OpenFlow 1.0 Switch Specification http://www.openflow.org/documents/openflow-spec-v1.0.0.pdf)
- OpenFlow 1.3 Switch Specification https://www.opennetworking.org/images/stories/downloads/specification/openflow-spec-v1.3.1.pdf
- Challenges of Service Provisioning in MPLS OpenFlow, Dávid Jocha, András Kern, Zoltán Lajos Kis, Attila Takács, WTC 2012, Japan http://www.fp7-sparc.eu/assets/publications/19-WTC_2012_SDN_Workshop_Sparc.pdf
- Station and Media Access Control Connectivity Discovery - 802.1AB-2009
- Generic Routing Encapsulation - IETF RFC2784
- Bidirectional Forwarding Detection - IETF RFC5880
Biography:
Zoltán Lajos Kis is a Research Engineer, working in the Packet Technologies division of Ericson Research in Budapest, Hungary.
He received his degree in computer science from Budapest University of Technology and Economics in 2004. After participating in research projects on distributed algorithms and network management, he started working with Ericsson in 2007. He worked as system engineer of several products in the telephony gateway and in the user database areas. He joined Ericsson Research in 2010, where he started working on the OpenFlow ecosystem.
He contributed to the 1.1 release of the OpenFlow protocol, and has been following the evolution of the protocol since. He has been a member of ONF's extensibility working group since the beginning, where he received ONF's Outstanding Technical Contribution award at the end of 2011.

In order to introduce SDN (Software Defined Networking) based virtual network as a flexible transport network service, reliability and QoS (Quality of Service) are important issues. Towards archiving reliability and QoS in virtual network, we have proposed SDN based multi-layer network control scheme where OpenFlow controller (OFC) can use MPLS-TP’s OAM (Operation, Administration and Maintenance) report.
In this presentation, we propose a system where a SDN based network and an application service cooperate each other to keep their QoS. Overview of the proposed system is shown in Fig. 1. We developed new interface between end-host application and OFC, so that end-host application can notify QoS alert to OFC. OFC also has interface to gather QoS alert of MPLS path from network nodes (PTN). To make QoS alert from PTNs, we use LM (Loss Measurement) and DM (delay measurement) of MPLS-TP OAM report.
We built a video streaming demonstration with the proposed system, as shown in Fig. 1. In the demo, the video-streaming sender starts its service using high bitrate video (HD). If receiver’s quality report (RR) notified frequent packet loss or buffer under-run, the sender changes its video rate to low (SD). If the sender still detected bad quality at the receiver even using SD video, the sender notify QoS alert to OFC. If OFC found QoS alerts from all PTNs on MPLS route between end-hosts, OFC set a new route which has no QoS alert. Then OFC clears QoS alert in the server and PTNs, and the server turns its video rate to HD.
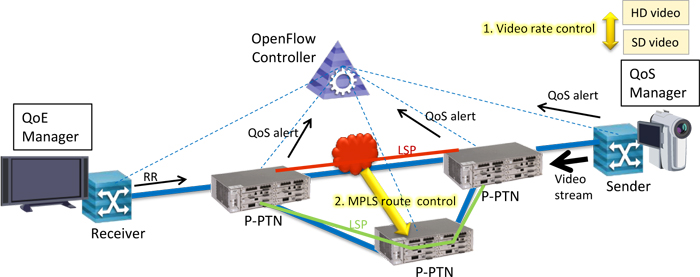 Fig.1 Overview of the proposed system and its demonstration.
Fig.1 Overview of the proposed system and its demonstration.
Acknowledgement:
This work is a part of “Research & Development of Basic Technologies for High Performance Opto-electronic Hybrid Packet Router” supported by National Institute of Information and Communications Technology (NICT).
Biography:
Yohei Hasegawa received his B.E. and M.E. degrees in Computer Science from Waseda University, Tokyo, Japan in 1997 and 1999, respectively. He joined NEC Corporation in 1999 and has been engaged in research on active networks, overlay networks, transport networks, network protocols and network measurement. From 2007 to 2008, he was a visiting scientist at the University of Massachusetts, Amherst. He received the Best Paper Award of the IEICE Transactions on Communications in 2010, and the Excellent Paper Award in AIAA ICSSC 2011, Information Networks Research Award from the IEICE Technical Committee on Information Networks in 2005, and Young Researcher Award from IEICE in 2005. He is a member of IEICE.

Software Defined Networks (SDN) based on the original OpenFlow (OF) only support packet networks; however the convergence of packet-circuit networks becomes necessary for increasing bandwidth demand and new applications, such as big data transfer. We developed a new SDN controller to support converged networks by augmenting OF to support protocol translation. The new SDN takes advantages of converged networks to support intelligent functionalities by adding situation-awareness, such as knowledge of protocols, link congestion, and/or quality of transmission (QoT). They are developed and experimentally demonstrated as follows (Fig. 1):
- Protocol and congestion aware multipath routing: Generally, OSPF paths with lowest latency (least hops) are best optimized paths for traffic. However, networks meet with traffic congestion when traffic volume exceeds the path bandwidth capacity and cause large packet loss. Our SDN controller is aware of the links’ bandwidth utilization, traffic protocols, and traffic requirements (e.g. video must be low latency and low jitter, big data must be low packet loss). The controller optimizes the path for each traffic type to avoid traffic congestion. In our experiment, when a big IP traffic is introduced, the controller will optimize it through optical nodes with higher bandwidth capacity (Fig. 1 App1).
- QoT-aware wavelength reassignment or path re-routing: The QoT is measured by the bit error rate (BER). In the electronic domain, BERe is measured by counting the error bits at switch’s ports. In the optical domain, BERo is directly related to the Optical Signal to Noise Ratio (OSNR), which is measured in real time by an OPM device. Under physical impairments, our SDN controller will re-assign a new clean wavelength for the impaired link or re-route the traffic to an alternative path (Fig. 1 App2).
The large-scale routing, network stability and resource optimization in Wide Area Network (WAN) are drivers for distributed converged SDN to make global decisions for big data transport. In our ongoing work, we are focusing on globalization of SDN through cross-controller communications.
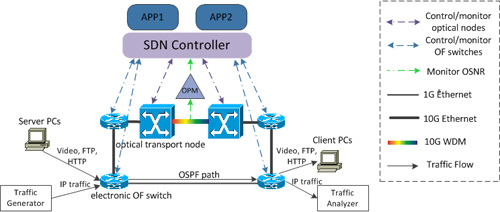 Fig.1 The SDN controller allowing situation-awareness and enabling new Apps in a converged SDN.
Fig.1 The SDN controller allowing situation-awareness and enabling new Apps in a converged SDN.
Biography:
Dr. Jun He is an Assistant Research Professor in the College of Optical Sciences at the University of Arizona. Dr. He received his Ph.D. in Electrical Engineering from the University of Virginia in 2008. His graduate research analyzed the cross-layer optimization of joint routing and resource allocation for optical networks impaired by physical degradations. His research interests include the architectural, algorithmic, and performance aspects of communication networks, with particular emphasis on wireless and optical networks. Dr. He has more than 30 publications in international refereed journals and conferences. He is associate editor for the Elsevier Computers and Electrical Engineering and has severed as member of the Technical Program Committee for IEEE ICNC 2014, WCNC 2011, and IEEE ICC 2010.

Since IP traffic has been growing by 30% a year, network carriers have to improve cost efficiency of their network as fast as the traffic growth. IP-offloading is an idea to reduce cost of IP routers in the network, using lower layer forwarding instead of IP forwarding. But, even with IP-offloading, most of edge-routers still have to remain in the network, because IP and BGP are the dominant for inter-operation with neighbor networks.
In order to reduce edge-routers, we propose BGP processing in OpenFlow controller (BGP-OC). We also propose a network architecture with BGP-OC and P-PTN (Programmable Packet Transport Node) [1], which is OpenFlow enabled IP/MPLS-TP node. The proposed network is designed to work as an IP router with BGP. An overview of the proposed network is shown in Fig. 1. In the proposed network, BGP packets are forwarded by P-PTN towards BGP-OC. BGP-OC controls P-PTN's IP/MPLS-TP forwarding in accordance with BGP transactions. BGP-OC also uses MPLS-TP statistics for faster IP route change through BGP. We implemented a test bed system of the proposed network architecture. We are going to have further study to verify the proposed ideas on the test bed.
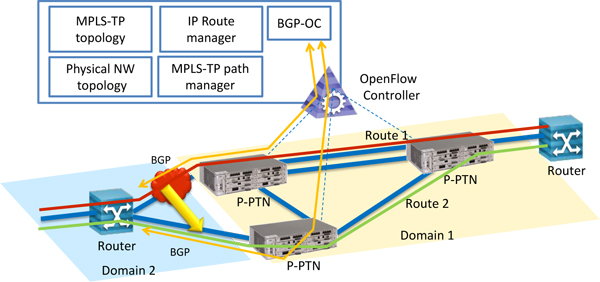 Fig.1 Overview of the proposed network.
Fig.1 Overview of the proposed network.
Acknowledgement:
This work is a part of “Research & Development of Basic Technologies for High Performance Opto-electronic Hybrid Packet Router” supported by National Institute of Information and Communications Technology (NICT).
References:
- Masahiro Hayashitani, “Design and Implementation of OpenFlow-enabled MPLS-TP Switch Prototype”in iPOP2012, May 2012.
Biography:
Yohei Hasegawa received his B.E. and M.E. degrees in Computer Science from Waseda University, Tokyo, Japan in 1997 and 1999, respectively. He joined NEC Corporation in 1999 and has been engaged in research on active networks, overlay networks, transport networks, network protocols and network measurement. From 2007 to 2008, he was a visiting scientist at the University of Massachusetts, Amherst. He received the Best Paper Award of the IEICE Transactions on Communications in 2010, and the Excellent Paper Award in AIAA ICSSC 2011, Information Networks Research Award from the IEICE Technical Committee on Information Networks in 2005, and Young Researcher Award from IEICE in 2005. He is a member of IEICE.

At Open Networking Summit 2011 Scott Shenker (with Martín Casado, Teemu Koponen, Nick McKeown, and others) gave a presentation outlining the general principles of Software Defined Networks. In this view SDN is based on three types of abstractions:
- A specification abstraction that provides a simplified model of network. This simplified view of the network can be configured, according to rules or policies set by the operator, and then mapped to physical configuration in the network.
- A distributed state abstraction that that gathers information from network elements and disseminates control commands to network elements.
- A forwarding abstraction that allows the expression of rules for packet forwarding. In this talk we will describe how these SDN abstractions have been implemented in a “Real-time OSS” that corresponds to the Network Operating System and Network Virtualization layers outlined by Shenker.
The Real - time OSS uses the following design principles:
- A single logical data store with a uniform interface holds all information regarding a network. This includes equipment inventory, network topology, device configurations and assessed device operational states, as well as configuration and operational state for all abstracted network services.
- All network devices and abstracted network services have data models defined in YANG, and the device models specifically list all configurable parameters and operational data variables.
-
The data store is kept consistent with respect to the actual network at all times. This principle can be further broken down into the following requirements:
- The configuration for added network devices is automatically discovered.
- Configuration changes are applied to network devices using a transactional mechanism, that either succeeds completely or fails with no changes performed.
- Network devices notifies the SDN controller about relevant changes to their operational state, but reserve the use of alarm notifications to the changes that require actions to be resolved.
-
The data store is kept internally consistent at all times. This principle can be further broken down into the following requirements:
- All configuration changes are validated using the applicable YANG schema.
- Abstracted network services define mappings that relate their configurations and operational states to the services and devices on which they depend, and these mappings are automatically maintained by the controller program.
- Any change in the data store can trigger a customized workflow. The Real-time OSS architecture is hierarchical and distributed. A central controller, which among other tasks keeps the main configuration data store for all network devices, is deployed at single site. Local controllers are deployed at various locations throughout the network. These local controllers implement the NETCONF and SNMP interfaces to the network devices. This interface is used for collection of notifications of alarm and events, as well as counters and other performance indicators, from network devices and for configuration of network devices. We will also discuss how this hybrid system relates to a pure Openflow-based architecture.
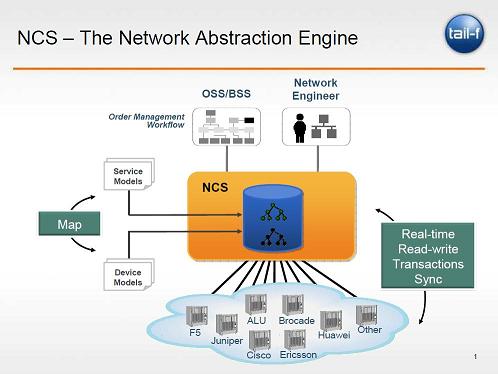 Fig.1
Fig.1
Biography:
Masa Iwashita started his career in software industry in 1986 and joined A.I.Corporation in 1995. Since then, he has been working on marketing, sales and business development of embedded software, in particular, network-related software. Since 2009, he has been working closely with Tail-f Systems, which A.I.Corporation represents as a distributor in Japan.

Networks will continue to evolve becoming more dynamic and agile. The vision of a Software Defined Network becomes more of a reality although requires closer investigation into the automation of Multi Layered networks. Here we will review some of the enabling technologies such as IP / DWDM Control Plane integration, PCE Centralized Computation and Network Planning and Optimization (NoS) tools.
Building on these enabling technologies we present a possible migration path that will exploit this automation and additional agility in the network that allow for the realization of a SDN architecture that will enable the dynamic addition / removal or proactive rerouting of capacity around the multi layer network. We shall highlight some of the benefits and economic savings associated with the discussed approaches.
Biography:
Zafar Ali is a Senior Technical Leader at Cisco Systems, Inc. where he leads software protocol development in Cisco Systems service provider routing group. Most recently Zafar has been focused on designing and developing Generalized MPLS and label switch multicast protocols and solutions. Prior to joining Cisco, Zafar worked at Nortel Networks and Hughes Network Systems. Overall he has over 15 years of industry experience.
Zafar Ali is quite active as a member of the MPLS, CCAMP, PCE, BFD, IDR, RTG, I2RS and other working group within IETF. He has authored a number of RFCs and IETF drafts. In addition, Zafar Ali has also authored several Journal papers, conference publications, white papers, patents, and book chapters. He is a regular presenter at MPLS conferences. Zafar Ali received his Ph. D. and MS in Electrical and Computer Engineering from Purdue University, West Lafayette, Indiana. He obtained his Bachelor of Engineering in Electrical Engineering from NED University, Karachi, Pakistan where he was awarded the University Gold Medal.

Cloud Computing Orchestration enables quick creation of new services and scaling of server resources. The on-demand arrangement of Storage, Compute and Network resources has enabled cost-effective, scalable systems to be created.
However, Orchestrators have been limited to connecting Servers to a virtual Ethernet infrastructure. As a result of this overly simplified networking model, it is not possible for the Orchestrator to understand details of the network. Attributes such as the economic cost, latency and congestion need to be considered by the Orchestrator when connecting cooperative computing elements. As a result, the scope which an orchestrator operates is often limited to a single datacenter.
The network may also have capacity and capabilities that reduce the economic cost for a service while optimizing the resources used to meet the attributes required by an application. These capabilities may include use of higher-speed lower layer connections (e.g. Optical Channel) instead of higher-cost upper-layer connections (e.g. IPv6) and the use of lower latency connections instead of paths that end up violating the required SLA.
Multi-layer routing methods enable a network controller to deliver these capabilities. By understanding the cross-layer network topology, the network controller can describe the connections possible along with the connection’s attributes. The Orchestrator is then able to select the set of servers and the network connections between them to meet an application’s requirements.
These methods are significantly effective when utilized with a network of a packet-optical network element. By selectively utilizing packet and optical switching, application requirements may be met while reducing the capital cost for delivering a service.
Biography:
Jonathan Sadler is a Senior Product Planner in the Optical Network Group at Tellabs.
With over 25 years of data communications experience as a protocol implementer, network element designer, carrier network operations manager, and carrier network planner, Jonathan brings a broad set of knowledge and experiences to the design and analysis of carrier network technology.
Currently, Jonathan is involved in the development of technologies providing the efficient transport of packet oriented services in carrier networks. Jonathan is the Chairman of the Optical Internetworking Forum's Technical Committee and an active participant in both ITU and IETF. Jonathan studied Computer Science at the University of Wisconsin - Madison.
- Tomonori Aoyama, Keio University, and GICTF, Japan
- Monique Morrow and Miya Kohno, Cisco, USA
- Rick McGeer, HP, USA
- Tomohiro Kudoh, AIST, Japan
- Hideki Kurihara, NTT Communications, Japan